kein anderes Web Content Management System?! Lassen Sie mich nCMS vorstellen
Verfasst in: Englisch / Veröffentlicht: 15.04.2022 / Lesezeit: 27 Minute(n)
Gibt es einen Grund, Ihr eigenes Web Content Management System (WCMS) zu erstellen? Es gibt bereits Hunderds von ihnen.
Das ist wahr und deshalb gibt es keinen offensichtlichen Grund, ein solches Projekt zu starten. Nur wenn wir nicht völlig zufrieden sind über das, was derzeit verfügbar ist, oder wir wollen nur lernen und versuchen, was es bedeutet, dies zu tun.
Ursprünglich wollte ich meine Website neu gestalten beihttps://niklas-stephan.de, aber dann hatte ich Spaß, von Grund auf zu beginnen und baute die meisten Backend auf meinem eigenen.
Und das ist die Absicht hinter nCMS, “niklas stephan’s Content Managment System” oder “node-red Content Management System” oder “nicht ein anderes Content Management System”.
Was ist nCMS und wozu ist es fähig?
nCMS ist ein kopfloses WCMS basierend auf einer flachen Hierachie, also im Vergleich zu z. Wort Drücken Sie, dass wir keine Datenbank oder eine traditionelle serverseitige Programmiersprache verwenden. Stattdessen nutzt das Backend meine Lieblings Low-Code-Plattform Node-Red, die von einer node.js Instanz bereitgestellt wird. So ist unsere Programmiersprache sowohl für Frontend als auch Backend reines JavaScript.
Änderungen in unserem Backend-Code werden implementiert, wie es bei der Verwendung von Node-Red üblich ist. Additonal irgendwelche Änderungen, die nicht direkt im Node-Red-Flow vorgenommen werden, basieren auf Dateien, die synchronisiert und in Github versionisiert werden. Auch das Frontend basiert auf Implementierungen, die extern über einen Webhook oder manuell innerhalb des Node-Red-Flusses gestartet werden. Sobald die Frontend-Bereitstellung gestartet ist, generiert alle benötigten Dateien und stellt sie als statische Dateien einem einfachen Webserver Ihrer Wahl zur Verfügung.
Fazit, dass eine Website erstellt mit nCMS extrem schnell. Um die Geschichte abzuschließen, muss man so sagen, dass, wenn wir einen (neuen) Beitrag erstellen/erarbeiten möchten, wir die Markup-Sprache verwenden und die Datei über jede Texteditor-Anwendung bearbeiten können.
Integrierte Merkmale sind (bisher):
- Multi-Language-Unterstützung für Beiträge und alle anderen Seiten
- Kommentar Managend für jeden Beitrag
- Ein einfacher Medienmanager
- Frontend HTML-Generation basierend auf Vorlagen und Snippets
- Vanilla JavaScript nur, keine Verwendung eines zusätzlichen Frameworks wie Vue oder Angular durch Absicht.
- Automatische Erstellung von Metadaten für die Integration von Social Media und Suchmaschinen.
- Eine interne Full-Text-Suchfunktionalität, die zusätzliche Serveranrufe veraltet macht.
- Veröffentlichen über einfaches Meta-Attribut
Und vieles mehr, dokumentiert und availabe bei den Projekten Github Repository:https://github.com/handtrixx/ncm
schneller, sauberer und schlanker als WordPress und ähnliches?
Ja, ja, ja. Ich werde hier erklären, warum und wie das erreicht wird.
Schnell
- Backend – eine sinlge Deplyoments (die Erstellung aller statischen Dateien für das Frontend erforderlich) Dauer beträgt zwischen 70 und 320 Millisekunden.
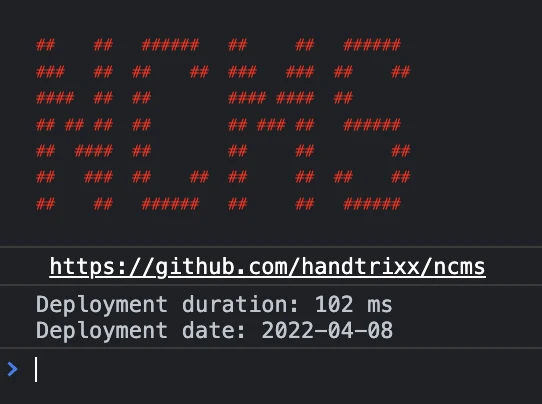
- Frontend – als Beispiel, auch durch starke Nutzung von Animationen, Bildern und anderen Effekten, die Größe der Frontage vonniklas-stephan.deist nicht mehr 700KB und kann extrem schnell als Flat-Dateien zwischen 100 – 300 Millisekunden bereitgestellt werden.

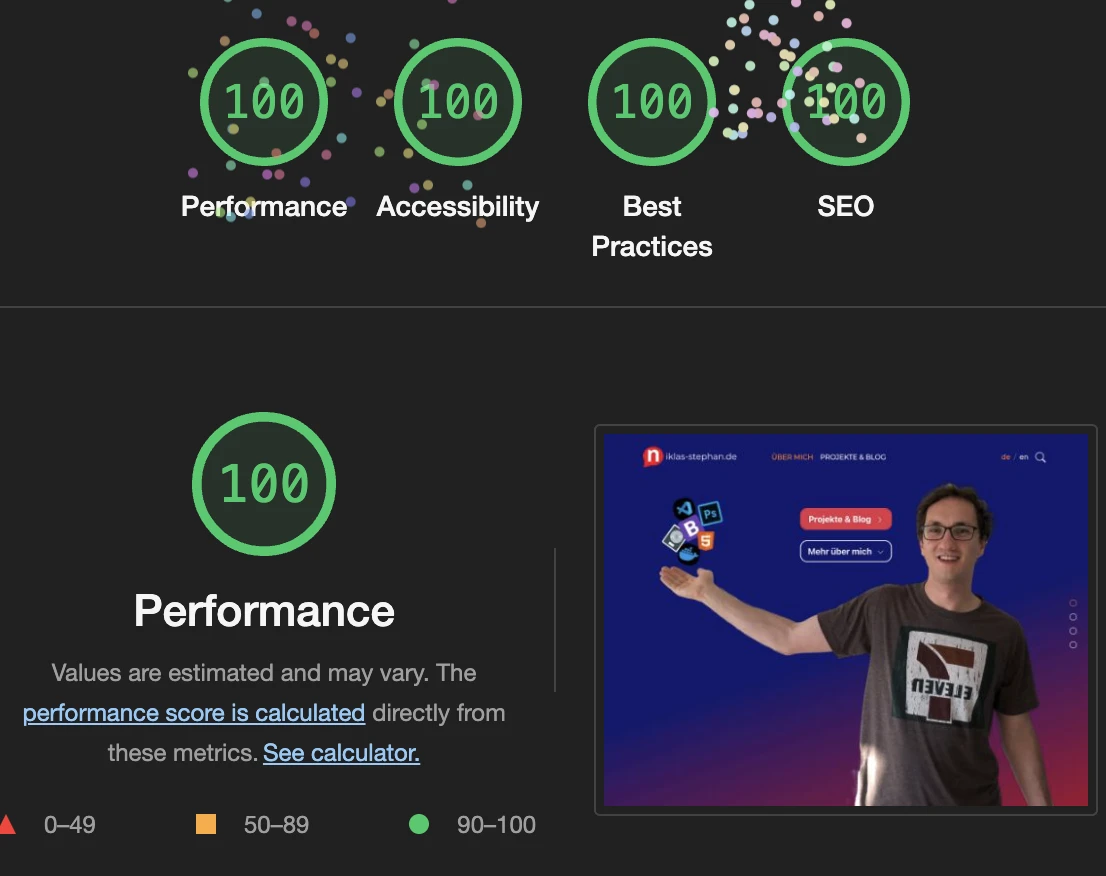
Sauberkeit
- Backend: Nur Overhead ist die Nutzung von Node-Red, die uns andererseits einen schönen grafischen Überblick über die Logik des kompletten Programms bietet.
- Frontend: Da keine zusätzlichen Rahmen verwendet werden, ist alles ganz einfach und sauber Code ist das Ergebnis. Während der Erstellunghttps://niklas-stephan.de, Ich habe zusätzlich die HTML5-Vorlagen von Bootstrap verwendet, aber auch das wurde viel sauberer und einfacher in seiner aktuellen Version 5.
Einfach
- Backend: Um Assets, Medien, Templates und Snippets zu bedienen, kann ein einfacher Editor wie Visual Studio Code oder dergleichen verwendet werden. Nett bei der Verwendung von VS-Code ist, dass es einschließlich SSH Zugriff auf den Server, GitHub Integration und Datei Manipulation Fähigkeiten. Dass mehr oder weniger alles, was wir neben einem Browser und einem Photoshop (Clone like Pixelmator) benötigen. In Node-Red bringen wir alle Quellen zusammen und erweitern die Programmlogik durch weitere js-Code und Nutzung mehrerer node.js-Module.
- Frontend: Die Auswahl der Sprache erfolgt automatisch, kann aber manuell überschrieben werden, indem Sie auf die gewünschte Sprache oben auf dem Bildschirm klicken. Es gibt eine Titelseite, darunter Links zu den anderen Bereichen wie der Suchseite, der Datenschutz- und Impressumsseite und der Blogseite. Außerdem haben wir eine 404 Fehlerseite, um Anrufe auf nicht (mehr) bestehende Seiten zu fangen.
Keine Notwendigkeit zu erwähnen, dass das Frontend optimiert wird, um nett auf jeder Art von Browser-Gerät angezeigt werden.
Hinter den Kulissen
Eine Docker-Compose-Umgebung wird verwendet, um ncms zu hosten. Sie können den Quellinhalt des Volumens findensrcbeihttps://github.com/handtrixx/ncm.
Inhaltdocker-compose.ymlwird hier gezeigt und basierend auf dem offiziellen Nod-Red-Bild von Docker Hub (https://hub.docker.com/r/nodered/node-red:
version: "3.0"
services:
ncms:
container_name: ncms
hostname: ncms
image: nodered/node-red:latest
restart: always
environment:
- TZ=Europe/Berlin
networks:
- dmz
logging:
options:
max-size: "10m"
max-file: "3"
volumes:
- ./data:/data
- ./dist:/dist:rw
- ./src:/src:rw
- /etc/localtime:/etc/localtime:ro
networks:
dmz:
external: true
Nicht viel zu erklären, denn es ist relativ nach vorne. Vielleicht sind die unterschiedlichen Volumina und die Netzwerkkonfiguration zu erwähnen. Genau wie die meisten in meinen anderen webbezogenen Beiträgen, nutze ich das nginx Managment-Tool “Nginx Proxy Manager” als umgekehrte Proxy (https://hub.docker.com/r/jc21/nginx-proxy-manager) Das Volumenversion: "3.0"
services:
ncms:
container_name: ncms
hostname: ncms
image: nodered/node-red:latest
restart: always
environment:
- TZ=Europe/Berlin
networks:
- dmz
logging:
options:
max-size: "10m"
max-file: "3"
volumes:
- ./data:/data
- ./dist:/dist:rw
- ./src:/src:rw
- /etc/localtime:/etc/localtime:ro
networks:
dmz:
external: true
Unsere Umwelt ist Schmutz mit dem umgekehrten Proxy über symbolische Verbindung verbunden./dist. So müssen wir die Dateien während der Bereitstellung nicht zweimal kopieren oder generieren und die direkt verfügbare Datei ohne zusätzliche Webserverinstanz haben.
Die Node-Red GUI wird durch Konfiguration an einer separaten Subdomain erreichbar.
Dateisystem-Setup
Direktln -senthält folgende Unterordner, die manuell erstellt werden sollen:
- Vermögenswerte
- cs
- Schriftarten
- in
- j)
- Json
- md
- Beiträge
- Medien
- x
- Nippel
- Vorlagen
Ordner./srcund seine Unterordner halten alle Vermögenswerte wie die Quellen von Bootstrap 5 (https://getbootstrap.com/) und sicher unsere eigenen css-Stile und Javascript-Funktionen. Unterverzeichnisassetsenthält nur unsere statischen Übersetzungen.
Verzeichnisjsonund sein Unterordnermdenthält unsere Postdateien, die durch einepostsSuffix.
Unsere Bilder und andere Mediendateien werden im Ordner platziert.md. Ich schrieb das System, um auch Unterordner für Dateien zu überprüfen, aber das derzeit auf funktioniert auf einer Ebene (so, Inhalt in einem Unter-Sub-Ordner wird ignoriert).
Später sehen wir, dass diese Dateien automatisch in das Speichern und Web-optimiertes Format konvertiert werdenmediaund additon wird auch eine Miniaturansicht erzeugt.
Alle HTML-Elemente, die wir mehr als ein Mal verwenden möchten, werden im Ordner gespeichert.webp.
Direktsnippetsenthält die Quellen für alle HTML-Seiten, auf denen wir unsere Snippets und andere Daten bei der späteren Bereitstellung enthalten.
Wenn Sie die Details sehen möchten, welche Dateien erstellt werden müssen und welche Inhalte sie enthalten könnten, überprüfen Sie bitte mein Github-Repository unter:https://github.com/handtrixx/ncm.
Vorlagen
Die Vorlagendateien sind:templates– Unsere Fehlerseite wird immer angezeigt, wenn eine angeforderte Seite einfach nicht existiert oder wenn ein Beitrag vielleicht noch nicht übersetzt wurde. Unsere404.htmlwird verwendet, um einen Überblick über alle vorhandenen veröffentlichten Beiträge, die gefiltert und auf verschiedene Weise sortiert werden können. Dieblog.htmlenthält einfach unsere Landing-Seite mit ihrem Inhalt. Eine besondere Rolle wird demindex.htmlDatei. Es wird von jedem Post als Vorlage verwendet, um sicherzustellen, dass alle Beiträge die gleiche UX liefern.post.htmlStattdessen ist eine einfache Vorlage, um den Inhalt unserer Datenschutzerklärung und den Aufdruck bereitzustellen, der von jeder Seite durch EU-Recht direkt erreichbar ist. Dieprivacy-policy.htmlTemplate wird verwendet, um Suchmaschinen-Crawler einige grundlegende Informationen über unsere Website zur Verfügung zu stellen. Endlich gibt esrobots.txtVorlage, die die lokal indizierte Suchfunktionalität des Frontends umfasst.
Snippets
Die sogenannten Snippets sind grundlegende Komponenten, die auf jede Template-basierte Seite eingefügt werden. Sie werden getrennt, um Zeit zu sparen und unseren Code sauber zu halten. So zum Beispiel eine Änderung des Navigationsschnipselssearch.htmlwird automatisch auf allen Seiten reflektiert.
Die verwendeten Nippel sind:navbar.html,footer.html,head.html,navbar.html.
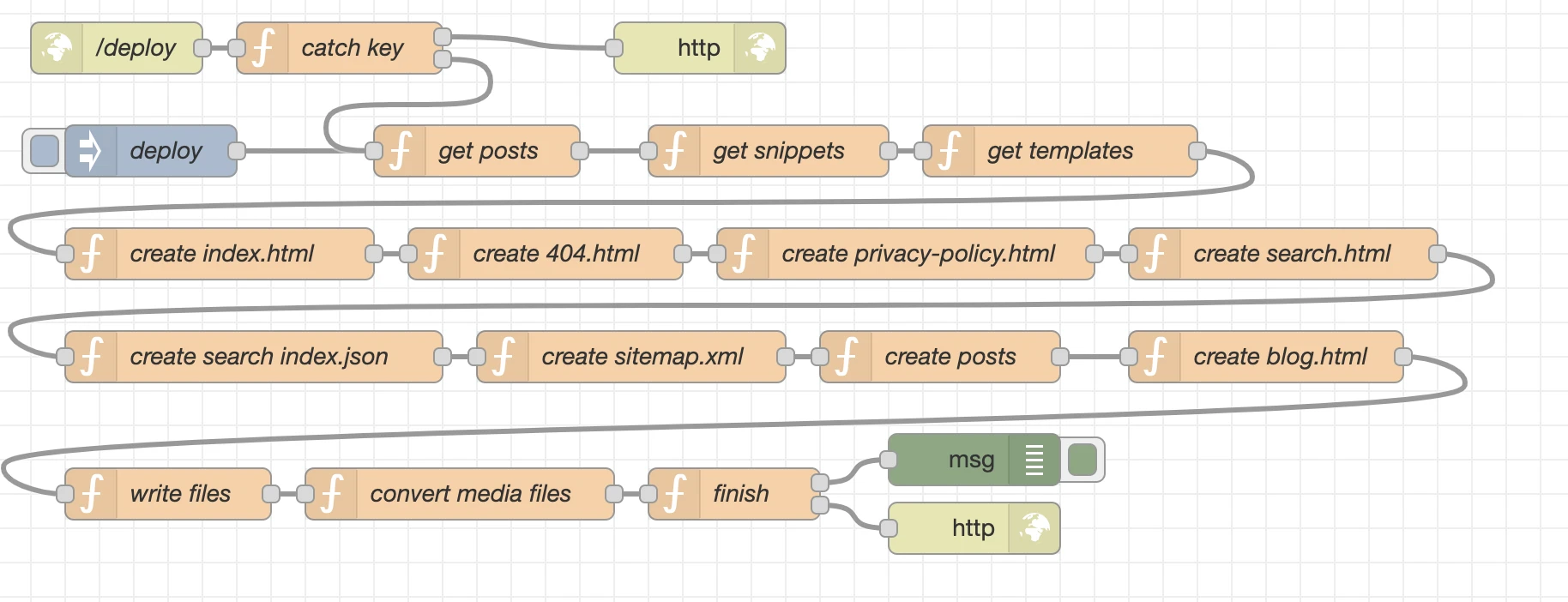
node.js and Node-Red program backend logic
Nod-Red selbst basiert auf node.js und einer Plattform zur Low-Code-Programmierung von ereignisgetriebenen Anwendungen. Wir können so genannte Knoten verwenden, die beispielsweise eine Javascript-Funktion darstellen können und dann viele dieser Knoten als Fluss verknüpfen.
Für nCMS verwenden wir fast nur diese Fähigkeiten, aber ignorieren Sie den "Low-Code" Teil ein bisschen, da wir nur mit vollen geblasenen Javascript-Funktionen arbeiten.
Was wir stattdessen tun, um andere npm-Module bei Bedarf in die spezifischen Knoten zu integrieren, was einfach über jeden Nodes-Setup-Tab erfolgen kann.
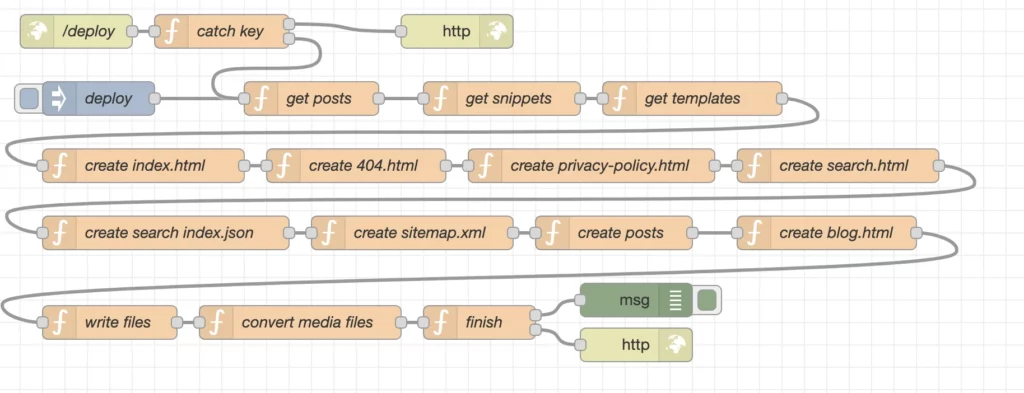
Weitere Informationen zu den erstellten Knoten und deren Details finden Sie hier.
/ Bereitstellung
Diescript.htmlKnoten ist einfach/deploydie es uns ermöglicht, unsere Bereitstellungen durch einen Webhook zu starten. Das bedeutet, indem man z.http invon überall starten wir eine Anfrage für ein Deplyoment.
Fangschlüssel
Sicher, dass wir nicht zulassen wollen, dass nur jemand den Einsatz startet, also diecurl -X POST -d 'key=----' https://ncms.niklas-stephan.de/deploynode vergleicht die vom Webhook-Call gesendete "key"-Variable mit einem in unserem Backend gespeicherten geheimen Schlüssel.catch keyOrdner unserer Docker Umgebung, um sicher zu sein, dass wir nicht versehentlich synchronisieren, dass Schlüssel zu Github sowie.
Wie bereits erwähnt, fügen wir ein additioanl npm Modul hinzudataund machen es availabel alsfs-extraauf der Setup-Tab des Knotens.
Damit können wir auf das Container-Dateisystem zugreifen, um die Schlüssel zu vergleichen.
Die komplette Funktion im Knoten ist:
fse
Es ist zu erwähnen, dass dieser Knoten zwei Austrittspfade aufweist. Exit one wird verwendet, wenn die Tasten übereinstimmen und das Deplyoment fortsetzen, während Ausgang zwei aufgerufen wird, wenn die Authentifizierung ausfällt und das Deplyoment abbrechen wird.
Bereitstellung
Dieconst transferedKey = msg.payload.key;
const systemKey = fse.readFileSync('/data/deploy.key', 'utf8')
if (transferedKey == systemKey) {
msg.payload = "Deployment Started";
msg.statusCode = 200;
msg.type = "webhook";
msg.starttime = Date.now();
return [null,msg];
} else {
msg.payload = "Wrong authentication!"
msg.statusCode = 400;
return [msg,null];
}
node ist zum Starten einer Bereitstellung manuell durch Klicken auf die Node-Red GUI.
Ich habe keine
Die 28 Linien derconst transferedKey = msg.payload.key;
const systemKey = fse.readFileSync('/data/deploy.key', 'utf8')
if (transferedKey == systemKey) {
msg.payload = "Deployment Started";
msg.statusCode = 200;
msg.type = "webhook";
msg.starttime = Date.now();
return [null,msg];
} else {
msg.payload = "Wrong authentication!"
msg.statusCode = 400;
return [msg,null];
}
Knoten sind genug, um viel zu erreichen. Die Funktion wird alle Beiträge lesen, die wir erstellt haben und das Markup in gültiges HTML konvertieren. Außerdem manipuliert es die Quellen durch Änderung von Links, Bildern und Extraktion der in dendeployDateien. Jeder Ausgang wird in einem Array für eine spätere Nutzung gespeichert.
Neben der bereits bekanntenget postsnpm Pakete, die wir einrichten.mdund Plugins dafür.
Markdown-it (https://github.com/markdown-it/markdown-it) macht die Magie der Umwandlung von Markup zu HTML und der Hauptgrund, warum unser eigener Code so einfach ist, wie 28 Zeilen sein können.
fs-extra
schnippets
Wieder verwenden wirmarkdown-itModul in unserer Funktion, diesmal, um den Inhalt frorm jeden Schnipsel zu lesen, um es in unserem Fluss als Array zu speichernmsg.baseurl = "https://niklas-stephan.de"
msg.dist = {};
msg.posts = [];
const path = '/src/md/posts/';
const postfiles = fse.readdirSync(path)
const alength = postfiles.length;
for (var i=0; i<alength; i++) {
var srcFile = path+postfiles[i];
var distFilename = postfiles[i].split('.')[0]+".html";
var srcContent = fse.readFileSync(srcFile, 'utf8')
var md = new markdownIt({
html: true,linkify: true,typographer: true,breaks: true})
.use(markdownItFrontMatter, function(metainfo) {meta = JSON.parse(metainfo);})
.use(markdownItLinkifyImages, {target: '_blank',linkClass: 'custom-link-class',imgClass: 'custom-img-class'})
.use(markdownItLinkAttributes, { attrs: {target: "_blank",rel: "noopener",}
});
distContent = md.render(srcContent);
let data = {"srcFile":""+srcFile+"","srcContent":""+srcContent+"","distContent":""+distContent+"","distFilename":""+distFilename+"",...meta};
msg.posts.push(data)
}
return msg;
.
msg.baseurl = "https://niklas-stephan.de"
msg.dist = {};
msg.posts = [];
const path = '/src/md/posts/';
const postfiles = fse.readdirSync(path)
const alength = postfiles.length;
for (var i=0; i<alength; i++) {
var srcFile = path+postfiles[i];
var distFilename = postfiles[i].split('.')[0]+".html";
var srcContent = fse.readFileSync(srcFile, 'utf8')
var md = new markdownIt({
html: true,linkify: true,typographer: true,breaks: true})
.use(markdownItFrontMatter, function(metainfo) {meta = JSON.parse(metainfo);})
.use(markdownItLinkifyImages, {target: '_blank',linkClass: 'custom-link-class',imgClass: 'custom-img-class'})
.use(markdownItLinkAttributes, { attrs: {target: "_blank",rel: "noopener",}
});
distContent = md.render(srcContent);
let data = {"srcFile":""+srcFile+"","srcContent":""+srcContent+"","distContent":""+distContent+"","distFilename":""+distFilename+"",...meta};
msg.posts.push(data)
}
return msg;
Vorlagen erhalten
Und eine weitere Zeit, das gleiche für die Vorlagen zu tun und sie als Objekte zu speichernfs-extra.
msg.snippets
erstellen index.html
Jetzt können wir beginnen, unsere HTML-Dateien für die Ausgabe vorzubereiten. Erst gehen wir mitmsg.snippets = {};
const path = '/src/snippets/';
const files = fse.readdirSync(path)
const alength = files.length;
for (var i=0; i<alength; i++) {
var srcFile = path+files[i];
var srcContent = fse.readFileSync(srcFile, 'utf8')
msg.snippets[files[i]] = srcContent;
}
return msg;
, wo wir zunächst die Seiten bestimmte Metadaten generieren und einfügen und dann die Platzhalter der Vorlage durch den Inhalt unserer Schnipsel ersetzen.
Auch setzen wir einen Seitentitel, um endlich den generierten Inhalt zu speichern alsmsg.snippets = {};
const path = '/src/snippets/';
const files = fse.readdirSync(path)
const alength = files.length;
for (var i=0; i<alength; i++) {
var srcFile = path+files[i];
var srcContent = fse.readFileSync(srcFile, 'utf8')
msg.snippets[files[i]] = srcContent;
}
return msg;
die später verwendet werden, um unseremsg.templatesDatei.
msg.templates = {};
const path = '/src/templates/';
const files = fse.readdirSync(path)
const alength = files.length;
for (var i=0; i<alength; i++) {
var srcFile = path+files[i];
var srcContent = fse.readFileSync(srcFile, 'utf8')
msg.templates[files[i]] = srcContent;
}
return msg;
404.html erstellen
Die Erstellung unserer Fehlerseiteninhalte erfolgt schnell. Auch hier legen wir den Inhalt der Snippets ein und setzen einen Seitentitel.
All das kann dann verwendet werden, um zu schreibenmsg.templates = {};
const path = '/src/templates/';
const files = fse.readdirSync(path)
const alength = files.length;
for (var i=0; i<alength; i++) {
var srcFile = path+files[i];
var srcContent = fse.readFileSync(srcFile, 'utf8')
msg.templates[files[i]] = srcContent;
}
return msg;
vonindex.htmlspäter.
msg.dist.index
erstellen privacy-policy.html
Gleiches bezüglich der Datenschutzseite, die wir alsindex.htmlObjekt durch folgendes Skript.
msg.dist.index = "";
var ogmetalang = "de_DE";
var ogmeta = `
<meta property="og:type" content="website">
<meta property="og:locale" content="`+ogmetalang+`">
<meta property="og:site_name" content="niklas-stephan.de">
<link rel="canonical" href="`+msg.baseurl+`/index.html">
<meta name="description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta property="og:title" content="Projects & Blog - niklas-stephan.de">
<meta property="og:description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta property="og:url" content="`+msg.baseurl+`/index.html">
<meta property="og:image" content="`+msg.baseurl+`/assets/img/me_logo.webp">
<meta property="og:image:secure_url" content="`+msg.baseurl+`/assets/img/me_logo.webp">
<meta name="twitter:card" content="summary">
<meta name="twitter:description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta name="twitter:title" content="Projects & Blog - niklas-stephan.de">
<meta name="twitter:image" content="`+msg.baseurl+`/assets/img/me_logo.webp">`
msg.dist.index = msg.templates["index.html"].replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
msg.dist.index = msg.dist.index.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
msg.dist.index = msg.dist.index.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
msg.dist.index = msg.dist.index.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
msg.dist.index = msg.dist.index.replace("<!-- PAGE TITLE -->","Home");
msg.dist.index = msg.dist.index.replace("<!-- meta tags -->",ogmeta);
return msg;
Suche erstellen.html
Bevor Sie ein bisschen komplexer die einfache Generation dermsg.dist.index = "";
var ogmetalang = "de_DE";
var ogmeta = `
<meta property="og:type" content="website">
<meta property="og:locale" content="`+ogmetalang+`">
<meta property="og:site_name" content="niklas-stephan.de">
<link rel="canonical" href="`+msg.baseurl+`/index.html">
<meta name="description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta property="og:title" content="Projects & Blog - niklas-stephan.de">
<meta property="og:description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta property="og:url" content="`+msg.baseurl+`/index.html">
<meta property="og:image" content="`+msg.baseurl+`/assets/img/me_logo.webp">
<meta property="og:image:secure_url" content="`+msg.baseurl+`/assets/img/me_logo.webp">
<meta name="twitter:card" content="summary">
<meta name="twitter:description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta name="twitter:title" content="Projects & Blog - niklas-stephan.de">
<meta name="twitter:image" content="`+msg.baseurl+`/assets/img/me_logo.webp">`
msg.dist.index = msg.templates["index.html"].replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
msg.dist.index = msg.dist.index.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
msg.dist.index = msg.dist.index.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
msg.dist.index = msg.dist.index.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
msg.dist.index = msg.dist.index.replace("<!-- PAGE TITLE -->","Home");
msg.dist.index = msg.dist.index.replace("<!-- meta tags -->",ogmeta);
return msg;
Objekt, das den Inhalt unserer Suchseite hält.
404.html
Suchindex erstellen. Json
Nun wollen wir unseren Suchindex aufbauen, der, wie bereits erwähnt, erstellt wird, damit unser Besucher unsere Blog-Inhalte durchsuchen kann, ohne einzelne Server-Anfragen zu starten. Um diesen Index alsmsg.dist.errorpagefür späteres Schreibenmsg.dist.errorpage = "";
msg.dist.errorpage = msg.templates["404.html"].replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
msg.dist.errorpage = msg.dist.errorpage.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
msg.dist.errorpage = msg.dist.errorpage.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
msg.dist.errorpage = msg.dist.errorpage.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
msg.dist.errorpage = msg.dist.errorpage.replace("<!-- PAGE TITLE -->","Page not found");
return msg;
wir verwenden eine Schleife, die durch alle Elemente gehtmsg.dist.errorpage = "";
msg.dist.errorpage = msg.templates["404.html"].replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
msg.dist.errorpage = msg.dist.errorpage.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
msg.dist.errorpage = msg.dist.errorpage.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
msg.dist.errorpage = msg.dist.errorpage.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
msg.dist.errorpage = msg.dist.errorpage.replace("<!-- PAGE TITLE -->","Page not found");
return msg;
(unsere Beiträge) und speichern sie als Json-Objekt.
msg.dist.privacy
Sitemap erstellen.xml
Ähnlich wie der Suchindex ist die Erstellung unserer Sitemap. Anstelle einer Schleife verwenden wir hier diemsg.dist.privacy = "";
msg.dist.privacy = msg.templates["privacy-policy.html"].replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
msg.dist.privacy = msg.dist.privacy.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
msg.dist.privacy = msg.dist.privacy.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
msg.dist.privacy = msg.dist.privacy.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
msg.dist.privacy = msg.dist.privacy.replace("<!-- PAGE TITLE -->","Datenschutz & Impressum");
return msg;
Funktion, die im Grunde das gleiche, aber etwas schöner und modern in vielen Aspekten tut.
msg.dist.privacy = "";
msg.dist.privacy = msg.templates["privacy-policy.html"].replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
msg.dist.privacy = msg.dist.privacy.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
msg.dist.privacy = msg.dist.privacy.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
msg.dist.privacy = msg.dist.privacy.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
msg.dist.privacy = msg.dist.privacy.replace("<!-- PAGE TITLE -->","Datenschutz & Impressum");
return msg;
erstellen
Während wir den Inhalt unserer Posts bereits erstellt haben und auf Array gespeichert habenmsg.dist.searchindex, wir müssen sie immer noch erweitern, um die Schnipseldaten sowie die Social Media Tags zu jedem von ihnen hinzuzufügen. Sobald jeder Post erledigt ist als Objekt verfügbarmsg.dist.search = "";
msg.dist.search = msg.templates["search.html"].replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
msg.dist.search = msg.dist.search.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
msg.dist.search = msg.dist.search.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
msg.dist.search = msg.dist.search.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
msg.dist.search = msg.dist.search.replace("<!-- PAGE TITLE -->","Suche");
return msg;
.
msg.dist.search = "";
msg.dist.search = msg.templates["search.html"].replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
msg.dist.search = msg.dist.search.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
msg.dist.search = msg.dist.search.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
msg.dist.search = msg.dist.search.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
msg.dist.search = msg.dist.search.replace("<!-- PAGE TITLE -->","Suche");
return msg;
Blog erstellen.html
Bevor wir endlich alle generierten Dateien auf die Festplatte schreiben können, müssen wir uns noch um unsere Blog-Seite kümmern.
Wie Sie sehen können, enthält die Funktion ein wenig mehr Aktion dann die meisten anderen Funktionen.
Grundsätzlich schleifen wir alle Beiträge durch, um die in ihren Metadaten definierten Kategorien zu erfassen und als Array zu speichern.
Dann entfernen wir alle douplicate Einträge aus diesem Array. Im nächsten Schritt geben wir jeder Kategorie eine Farbe zu, die auch in unserer Frontend-Datei “style.css” definiert sind.
Wir müssen auch die Meta-Daten von jedem Beitrag zu extrahieren, um ihre Vorschauen zu erstellen: den Titel, die Beschreibung, das Datum erstellen und das Vorschaubild. Hier haben wir auch eine, wenn Aussagen zur Vermeidung von nicht veröffentlichten Beiträgen berücksichtigt werden.
Der Rest ist wie zuvor, wir setzen die Metadaten der Seite und injizieren die Daten der Schnipsel, um schließlich alles als Objekt zu speichernmsg.dist.searchindex.
index.json
Schreiben von Dateien
Jetzt wollen wir alle generierten Objekte an schreibenmsg.postszu Dateien.
Dazu wird die Funktion "Dateien schreiben" auch mit npm Paket verwendetvar alength = msg.posts.length;
var index = "[";
for (var i=0; i<alength; i++) {
index = index+`{"lang":"`+msg.posts[i].language+`","link":"/posts/`+msg.posts[i].distFilename+`","headline":"`+msg.posts[i].title+`","content":"`+msg.posts[i].distContent.replace(/[^a-zA-Z0-9]/g, ' ')+`"},`;
}
index = index.slice(0, -1);
index = index+"]";
msg.dist.searchindex = index;
return msg;
wievar alength = msg.posts.length;
var index = "[";
for (var i=0; i<alength; i++) {
index = index+`{"lang":"`+msg.posts[i].language+`","link":"/posts/`+msg.posts[i].distFilename+`","headline":"`+msg.posts[i].title+`","content":"`+msg.posts[i].distContent.replace(/[^a-zA-Z0-9]/g, ' ')+`"},`;
}
index = index.slice(0, -1);
index = index+"]";
msg.dist.searchindex = index;
return msg;
.
Nach einer allgemeinen Aufräumung des ZielsforEach(), um Unstimmigkeiten zu vermeiden, erstellen wir die grundlegende Dateistruktur.
Durch die Nutzung des Befehls "erwarten" stellen wir sicher, dass die Erstellung dieser Verzeichnisse beendet ist, bevor wir auf die nächsten Schritte vorangehen.
Dann kopieren wir alle unsere Vermögenswerte vonvar xml = `<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.sitemaps.org/schemas/sitemap/0.9 http://www.sitemaps.org/schemas/sitemap/0.9/sitemap.xsd">
<url>
<loc>`+msg.baseurl+`/</loc>
<priority>1.00</priority>
</url>
<url>
<loc>`+msg.baseurl+`/index.html</loc>
<priority>0.80</priority>
</url>
<url>
<loc>`+msg.baseurl+`/blog.html</loc>
<priority>0.80</priority>
</url>`
msg.posts.forEach(postxml);
xml = xml + `
</urlset>`
msg.dist.sitemap = xml;
return msg;
function postxml(item) {
if (item.published == true ) {
xml = xml + `
<url>
<loc>`+msg.baseurl+`/posts/`+item.distFilename+`.html</loc>
<priority>0.64</priority>
</url>`
}
}
bisvar xml = `<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.sitemaps.org/schemas/sitemap/0.9 http://www.sitemaps.org/schemas/sitemap/0.9/sitemap.xsd">
<url>
<loc>`+msg.baseurl+`/</loc>
<priority>1.00</priority>
</url>
<url>
<loc>`+msg.baseurl+`/index.html</loc>
<priority>0.80</priority>
</url>
<url>
<loc>`+msg.baseurl+`/blog.html</loc>
<priority>0.80</priority>
</url>`
msg.posts.forEach(postxml);
xml = xml + `
</urlset>`
msg.dist.sitemap = xml;
return msg;
function postxml(item) {
if (item.published == true ) {
xml = xml + `
<url>
<loc>`+msg.baseurl+`/posts/`+item.distFilename+`.html</loc>
<priority>0.64</priority>
</url>`
}
}
, wie wir in Bezug auf diemsg.postsDatei.
Letzter Schritt ist, alle Dateien und jede Post-Datei zu erstellen, basierend auf dem Objektnamen (Schlüssel) durch eine Schleife, ausmsg.dist.posts.
msg.dist.posts = {};
var alength = msg.posts.length;
var data = "";
var ogmetalang = "";
var ogmeta = "";
var postdate = "";
for (var i=0; i<alength; i++) {
if (msg.posts[i].language == "de") {
ogmetalang = "de_DE"
} else {
ogmetalang = "en_US"
}
img = msg.posts[i].imgurl.split('.')[0]+".webp";
ogmeta = `
<meta property="og:type" content="website">
<meta property="og:locale" content="`+ogmetalang+`">
<meta property="og:site_name" content="niklas-stephan.de">
<link rel="canonical" href="`+msg.baseurl+`/posts/`+msg.posts[i].language+`/`+msg.posts[i].distFilename+`">
<meta name="description" content="`+msg.posts[i].excerpt+`">
<meta property="og:title" content="`+msg.posts[i].title+`">
<meta property="og:description" content="`+msg.posts[i].excerpt+`">
<meta property="og:url" content="`+msg.baseurl+`/posts/`+msg.posts[i].language+`/`+msg.posts[i].distFilename+`">
<meta property="og:image" content="`+msg.baseurl+`/media/full/`+img+`">
<meta property="og:image:secure_url" content="`+msg.baseurl+`/media/full/`+img+`">
<meta name="twitter:card" content="summary">
<meta name="twitter:description" content="`+msg.posts[i].excerpt+`">
<meta name="twitter:title" content="`+msg.posts[i].title+`">
<meta name="twitter:image" content="`+msg.baseurl+`/media/full/`+img+`">`
postdate = '<small class="c-gray pb-3" id="postdate">'+msg.posts[i].date+'</small>';
data = "";
data = msg.templates["post.html"];
data = data.replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
data = data.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
data = data.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
data = data.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
data = data.replace("<!-- mardown content from posts -->",msg.posts[i].distContent);
data = data.replace("<!-- Post Headline -->", msg.posts[i].title);
data = data.replace("<!-- postdate -->", postdate);
data = data.replace("<!-- Post Image -->", '<img src="/media/thumb/'+img+'" class="img-fluid mb-2" alt="postImage">');
data = data.replace("<!-- PAGE TITLE -->",msg.posts[i].title);
data = data.replace("<!-- meta tags -->",ogmeta);
msg.dist.posts[msg.posts[i].distFilename] = data;
}
return msg;
Mediendateien konvertieren
Ein bisschen Komplexität ist auch in Bezug auf unsere Mediendateien, die meist für Beiträge verwendet werden. Ich schrieb einen kleinen Medienmanager, der die Quelldatei in mehreren Ausgabeformaten konvertiert. Dies geschieht durch Erstellen einer Miniaturansicht, ein Platzsparenmsg.dist.posts = {};
var alength = msg.posts.length;
var data = "";
var ogmetalang = "";
var ogmeta = "";
var postdate = "";
for (var i=0; i<alength; i++) {
if (msg.posts[i].language == "de") {
ogmetalang = "de_DE"
} else {
ogmetalang = "en_US"
}
img = msg.posts[i].imgurl.split('.')[0]+".webp";
ogmeta = `
<meta property="og:type" content="website">
<meta property="og:locale" content="`+ogmetalang+`">
<meta property="og:site_name" content="niklas-stephan.de">
<link rel="canonical" href="`+msg.baseurl+`/posts/`+msg.posts[i].language+`/`+msg.posts[i].distFilename+`">
<meta name="description" content="`+msg.posts[i].excerpt+`">
<meta property="og:title" content="`+msg.posts[i].title+`">
<meta property="og:description" content="`+msg.posts[i].excerpt+`">
<meta property="og:url" content="`+msg.baseurl+`/posts/`+msg.posts[i].language+`/`+msg.posts[i].distFilename+`">
<meta property="og:image" content="`+msg.baseurl+`/media/full/`+img+`">
<meta property="og:image:secure_url" content="`+msg.baseurl+`/media/full/`+img+`">
<meta name="twitter:card" content="summary">
<meta name="twitter:description" content="`+msg.posts[i].excerpt+`">
<meta name="twitter:title" content="`+msg.posts[i].title+`">
<meta name="twitter:image" content="`+msg.baseurl+`/media/full/`+img+`">`
postdate = '<small class="c-gray pb-3" id="postdate">'+msg.posts[i].date+'</small>';
data = "";
data = msg.templates["post.html"];
data = data.replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
data = data.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
data = data.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
data = data.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
data = data.replace("<!-- mardown content from posts -->",msg.posts[i].distContent);
data = data.replace("<!-- Post Headline -->", msg.posts[i].title);
data = data.replace("<!-- postdate -->", postdate);
data = data.replace("<!-- Post Image -->", '<img src="/media/thumb/'+img+'" class="img-fluid mb-2" alt="postImage">');
data = data.replace("<!-- PAGE TITLE -->",msg.posts[i].title);
data = data.replace("<!-- meta tags -->",ogmeta);
msg.dist.posts[msg.posts[i].distFilename] = data;
}
return msg;
Datei und eine Kopie der Originaldatei vonmsg.dist.blogbis//get categories from all posts and extract unique ones
var categories = [];
for (var i=0 ; i<msg.posts.length;i++) {
if (msg.posts[i].published == true) {
for (var j = 0; j < msg.posts[i].keywords.length; j++) {
categories.push(msg.posts[i].keywords[j]);
}
}
}
var uniqueCategories = [...new Set(categories)];
// define a color to stick for each category
const colorcat = {};
var catcolors = ["green", "red", "blue", "orange", "yellow", "pink", "purple","indigo"];
var c=0;
for (const key of uniqueCategories) {
colorcat[key] = catcolors[c];
c = c+1;
}
//generate and set html for categorie selection
var cathtml = "";
for (var k = 0; k < uniqueCategories.length; k++) {
cathtml = cathtml + `<button data-filter=".cat-`+uniqueCategories[k]+`" type="button"
onclick="sort()" class="btn bg-` + catcolors[k] + ` c-white me-2">` + uniqueCategories[k]+`</button>`;
}
msg.dist.blog = msg.templates["blog.html"].replace("<!-- CATEGORIES -->", cathtml);
// get card content from all posts and generate html
var posthtml = "";
for (var l = 0; l < msg.posts.length; l++) {
if (msg.posts[l].published == true) {
var link = msg.posts[l].filename.slice(0, -3)+".html";
//get color for current post
var postcolor = "";
for (const key in colorcat) {
if (key == msg.posts[l].keywords[0]) {
postcolor = colorcat[key];
}
}
imgurl = msg.posts[l].imgurl.split('.')[0]+".webp";
posthtml = posthtml + `
<div class="col-sm-6 col-lg-4 my-4 filterDiv cat-`+msg.posts[l].keywords[0]+` lang-`+ msg.posts[l].language + `">
<span class="date hidden d-none">`+ msg.posts[l].date + `</span>
<span class="name hidden d-none">`+ msg.posts[l].title + `</span>
<div onclick="goto('`+ link+ `','blog')" class="card h-100 d-flex align-items-center bo-`+postcolor+`">
<div class="card-header bg-`+ postcolor + `">` + msg.posts[l].keywords[0] + `</div>
<div class="card-img-wrapper d-flex align-items-center">
<img src="media/thumb/`+ imgurl + `"
class="card-img-top" alt="iot">
</div>
<div class="card-body">
<h5 class="card-title">`+ msg.posts[l].title + `</h5>
<p class="card-text">
`+ msg.posts[l].excerpt + `
</p>
</div>
<div class="card-footer small text-center c-gray pdate">
`+msg.posts[l].date+`
</div>
</div>
</div>
`;
}
}
msg.dist.blog = msg.dist.blog.replace("<!-- POSTS -->", posthtml);
var ogmetalang = "de_DE";
var ogmeta = `
<meta property="og:type" content="website">
<meta property="og:locale" content="`+ogmetalang+`">
<meta property="og:site_name" content="niklas-stephan.de">
<link rel="canonical" href="`+msg.baseurl+`/blog.html">
<meta name="description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta property="og:title" content="Projects & Blog - niklas-stephan.de">
<meta property="og:description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta property="og:url" content="`+msg.baseurl+`/blog.html">
<meta property="og:image" content="`+msg.baseurl+`/assets/img/me_logo.webp">
<meta property="og:image:secure_url" content="`+msg.baseurl+`/assets/img/me_logo.webp">
<meta name="twitter:card" content="summary">
<meta name="twitter:description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta name="twitter:title" content="Projects & Blog - niklas-stephan.de">
<meta name="twitter:image" content="`+msg.baseurl+`/assets/img/me_logo.webp">`
msg.dist.blog = msg.dist.blog.replace("<!-- meta tags -->",ogmeta);
msg.dist.blog = msg.dist.blog.replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
msg.dist.blog = msg.dist.blog.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
msg.dist.blog = msg.dist.blog.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
msg.dist.blog = msg.dist.blog.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
msg.dist.blog = msg.dist.blog.replace("<!-- PAGE TITLE -->","Projekte & Blog");
return msg;
,//get categories from all posts and extract unique ones
var categories = [];
for (var i=0 ; i<msg.posts.length;i++) {
if (msg.posts[i].published == true) {
for (var j = 0; j < msg.posts[i].keywords.length; j++) {
categories.push(msg.posts[i].keywords[j]);
}
}
}
var uniqueCategories = [...new Set(categories)];
// define a color to stick for each category
const colorcat = {};
var catcolors = ["green", "red", "blue", "orange", "yellow", "pink", "purple","indigo"];
var c=0;
for (const key of uniqueCategories) {
colorcat[key] = catcolors[c];
c = c+1;
}
//generate and set html for categorie selection
var cathtml = "";
for (var k = 0; k < uniqueCategories.length; k++) {
cathtml = cathtml + `<button data-filter=".cat-`+uniqueCategories[k]+`" type="button"
onclick="sort()" class="btn bg-` + catcolors[k] + ` c-white me-2">` + uniqueCategories[k]+`</button>`;
}
msg.dist.blog = msg.templates["blog.html"].replace("<!-- CATEGORIES -->", cathtml);
// get card content from all posts and generate html
var posthtml = "";
for (var l = 0; l < msg.posts.length; l++) {
if (msg.posts[l].published == true) {
var link = msg.posts[l].filename.slice(0, -3)+".html";
//get color for current post
var postcolor = "";
for (const key in colorcat) {
if (key == msg.posts[l].keywords[0]) {
postcolor = colorcat[key];
}
}
imgurl = msg.posts[l].imgurl.split('.')[0]+".webp";
posthtml = posthtml + `
<div class="col-sm-6 col-lg-4 my-4 filterDiv cat-`+msg.posts[l].keywords[0]+` lang-`+ msg.posts[l].language + `">
<span class="date hidden d-none">`+ msg.posts[l].date + `</span>
<span class="name hidden d-none">`+ msg.posts[l].title + `</span>
<div onclick="goto('`+ link+ `','blog')" class="card h-100 d-flex align-items-center bo-`+postcolor+`">
<div class="card-header bg-`+ postcolor + `">` + msg.posts[l].keywords[0] + `</div>
<div class="card-img-wrapper d-flex align-items-center">
<img src="media/thumb/`+ imgurl + `"
class="card-img-top" alt="iot">
</div>
<div class="card-body">
<h5 class="card-title">`+ msg.posts[l].title + `</h5>
<p class="card-text">
`+ msg.posts[l].excerpt + `
</p>
</div>
<div class="card-footer small text-center c-gray pdate">
`+msg.posts[l].date+`
</div>
</div>
</div>
`;
}
}
msg.dist.blog = msg.dist.blog.replace("<!-- POSTS -->", posthtml);
var ogmetalang = "de_DE";
var ogmeta = `
<meta property="og:type" content="website">
<meta property="og:locale" content="`+ogmetalang+`">
<meta property="og:site_name" content="niklas-stephan.de">
<link rel="canonical" href="`+msg.baseurl+`/blog.html">
<meta name="description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta property="og:title" content="Projects & Blog - niklas-stephan.de">
<meta property="og:description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta property="og:url" content="`+msg.baseurl+`/blog.html">
<meta property="og:image" content="`+msg.baseurl+`/assets/img/me_logo.webp">
<meta property="og:image:secure_url" content="`+msg.baseurl+`/assets/img/me_logo.webp">
<meta name="twitter:card" content="summary">
<meta name="twitter:description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta name="twitter:title" content="Projects & Blog - niklas-stephan.de">
<meta name="twitter:image" content="`+msg.baseurl+`/assets/img/me_logo.webp">`
msg.dist.blog = msg.dist.blog.replace("<!-- meta tags -->",ogmeta);
msg.dist.blog = msg.dist.blog.replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
msg.dist.blog = msg.dist.blog.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
msg.dist.blog = msg.dist.blog.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
msg.dist.blog = msg.dist.blog.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
msg.dist.blog = msg.dist.blog.replace("<!-- PAGE TITLE -->","Projekte & Blog");
return msg;
,msg.dist. Das geschieht für alle Dateien des Typs “.gif”, “.jpg”, “.jpeg” und “.webp”. Alle anderen Dateien werden nur kopiert ohne Thumbnail-Generation oder Konvertierung.
Dazu verwenden wir npm Modulefs-extraundfse.
Zusätzlich zu erwähnen ist, dass wir nicht verwenden/distda die Datei-Erstellung einige Sekunden dauern kann, was zu einer längeren Depyloymentzeit führen würde. Stattdessen laufen diese Operationen im Hintergrund und weiter nach Deplyoment ist "offiziell" beendet. Das ist ein bisschen knifflig und vielleicht wird in der regelmäßigen Nutzung von nCMS geändert werden.
/src/assets/
Oberfläche
Wir sind fast fertig. Am "finsih"-Knoten berechnen wir einfach die Dauer jeder Bereitstellung und erstellen einen Zeitstempel.
Beide Informationen werden in die Datei geschrieben/dist/assets/, die vom Frontend aufgerufen wird, um seine Daten im Konsolenlogbuch des Besucherbrowsers anzuzeigen.
Je nachdem, ob die Bereitstellung manuell oder per Webhook angefordert wird, geben wir die Ergebnisse an beide oder nur einen der folgenden Knoten aus.
robots.txt
msg & http
Endlich sind wir fertig. Beide Knoten “msg” und “http” existieren nur, um ein sauberes Ende unserer Bereitstellung zu haben.
Mit dem „http out“ werden die Bereitstellungsinformationen als Feedback bereitgestellt, wenn die Bereitstellung über Webhook aufgerufen wurde.

Während der "msg" Debugknoten zeigt uns die Ausgabe des msg-Objekts unseres Flusses.
Hier können Sie den kompletten und bereits etwas korrigierten/modifizierten Node-Red-Flow herunterladen:https://niklas-stephan.de/media/orig/ncms/flow.json(Version 0.60).
Schlussfolgerung
Ich muss zugeben, dass das ganze Projekt etwas zeitraubend war. Aber von Anfang bis Ende wurde ich von dem Gedanken "nur diese eine noch kleine Sache" angetrieben und aufgeregt. Additonally hatte ich viel Spaß mit Node-Red zu erstellen und zu optimieren in mehr und mehr erweiterte Funktionen. Der integrierte Debugger und die schöne GUI sind äußerst hilfreich, um Fehler zu finden und jederzeit den Überblick zu behalten.
Die, zumindest für mich, neue Funktion, um zusätzliche node.js Module in meinen eigenen Funktionen einfach zu nutzen, machte den Trick für mich. Ansonsten wäre ich nicht in der Lage gewesen, das gleiche Ergebnis zu liefern oder zumindest nicht, dass fortgeschritten und gerade nach vorne, wie es ist, jetzt.
Wenn Sie jeden Plan ähnlich zu tun, sind Sie willkommen, mein Projekt zu verlassen oder einige Ideen zu fangen.
Sicher ist nCMS noch nicht perfekt.
Zum Beispiel machen alle Verweise auf das Frontend innerhalb meiner Funktionen es schwer, für andere zu lesen und zu verstehen.
Eigentlich der Fronted-Code und seine Funktionen, css und html wurde in meinem Post überhaupt nicht erwähnt. Vielleicht kann ich das noch mal machen.
Quellen / Links
Hier eine Zusammenfassung der meisten Quellen, Links und Dateien, die ich in meinem Beitrag erwähnte:
- nCMS bei Github:https://github.com/handtrixx/ncm
- Node-Red Flow für nCMS:https://niklas-stephan.de/media/orig/ncms/flow.json
- Die erstaunliche Node-Red:http://nodered.org/
- Node-Red als Container bei Docker Hub:https://hub.docker.com/r/nodered/node-red
- Ngnix Proxy Manager:http://nginxproxymanager.com/
- Die von Twitter erstellte Bootstrap HTML5 Vorlage:https://getbootstrap.com/
- markdown-it – Markup to HTML auf einfache Weise:https://markdown-it.github.io/
- Dateioperationen in node.js mit fs-extra:http://github.com/jprichardson/node-fs-extra
- ultra schnelle Bildkonvertierung im Knoten. js mit scharfen:https://sharp.pixelplumbing.com/