Noch ein Web Content Management System?! Ich stelle vor: nCMS
Verfasst in: Deutsch / Veröffentlicht: 15.04.2022 / Lesezeit: 26 Minute(n)
Warum sollte man sein eigenes Web Content Management System (WCMS) erstellen wollen, es gibt doch schon hunderte?!
Völlig korrekt und es gibt auch keinen wirklichen Grund so etwas zeitintensives zu tun, außer natürlich man ist mit dem was es gibt nicht so richtig zufrieden und/oder möchte einfach selber wissen und ausprobieren wie man so etwas angehen kann.
Genau mit dieser Motivation, und der ursprünglichen Intention für meine persönliche Website ein neues Layout zu entwickeln, habe ich mir innerhalb eines Monats ein eigenes WCMS erstellt: nCMS – “niklas stephan’s Content Management System” oder auch “node-red Content Management System” oder “not another Content Management System”!
Was ist nCMS und was kann es?
nCMS ist ein Flat-File und Headless Web Content Management System. D.h. im Gegensatz zu z.B. zu WordPress, kommt es ohne eine Datenbank aus und besteht aus Dateien. NCMS basiert im Backend auf Node-Red und darin entwickelten Node.js JavaScript Funktionen.
Änderungen am Code von NCMS werden durch Deployments in Node-Red geschrieben und die Änderungen an Dateien über GIT in Github synchronisiert und versioniert. Änderungen an Inhalten wie neue Posts werden ebenfalls über Deployments, manuell oder als Webhook gestartet. Alle Dateien werden darauf hin generiert und einem Webserver als statische Dateien zur Verfügung gestellt. Das heisst dass der Abruf der Inhate über eine mit nCMS erstellte Website rasend schnell ist. Das erstellen einzelner Blog Beiträge erfolgt in Markup Syntax in einem beliebigem Texteditor.
Weitere bis jetzt integrierte Features sind:
- Multi-Language Support für Blog Beiträge und alle Seiten
- Kommentarfunktion in den Blogbeiträgen
- Media Management über einfachen Datei-Upload
- Template- und Snippet-basierte Erstellung des HTML Gerüsts
- Explizit kein Einsatz von Frontend Frameworks wie Vue oder Angular, sondern reines “Vanilla” Javascript.
- Automatische Generierung von Meta-Daten für Social Media Integration und SEO
- Volltextsuche auf Basis eines automatisch generierten lokalen Index
- Freigabefunktion von Posts über ein “published” Attribut
Und viele mehr, dokumentiert im GitHub Repository des Projekts: https://github.com/handtrixx/ncms
Schneller, aufgeräumter und einfacher als WordPress und andere?
Ja, ja, ja. Wie genau, erläutere ich hier.
Schnell
- Backend – Ein Deployment (erzeugen der statischen Files für den Webserver) dauert zwischen 70 und 320 Millisekunden.
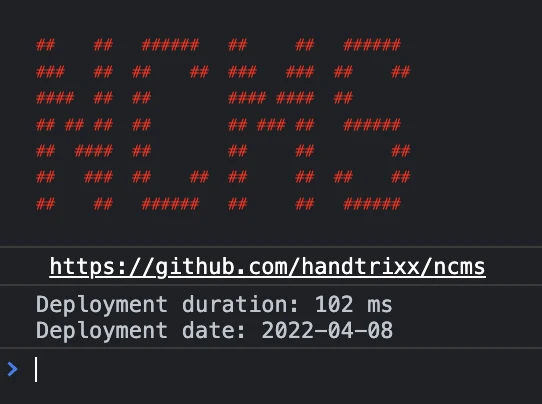
- Frontend – z.B. die Startseite ist trotz aller Animationen, Effekte und Bilder nur 670KB groß und kann in zwischen 100 und 300 Millisekunden vom Client vollständig geladen werden.

Aufgeräumt
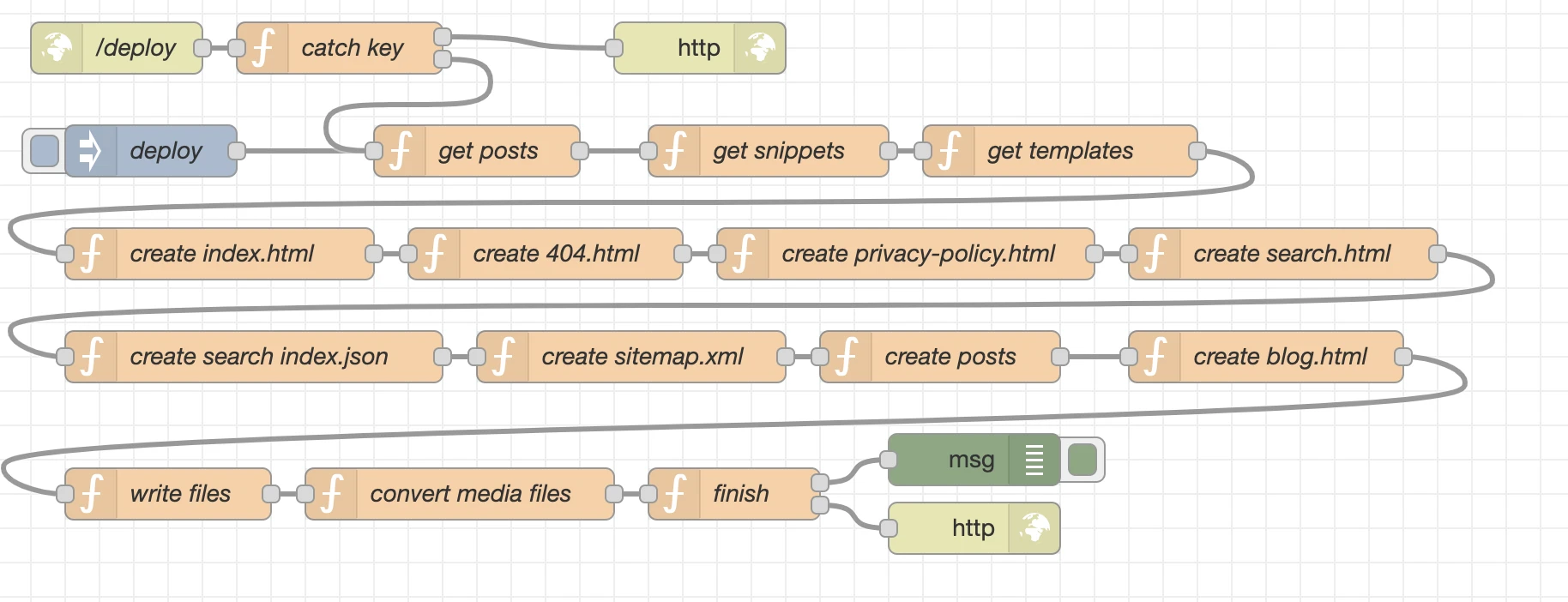
- Backend: Der Einsatz von Node-Red gibt eine grafische Übersicht und gewährleistet so, dass wir den Überblick nicht verlieren. Dazu später noch mehr.
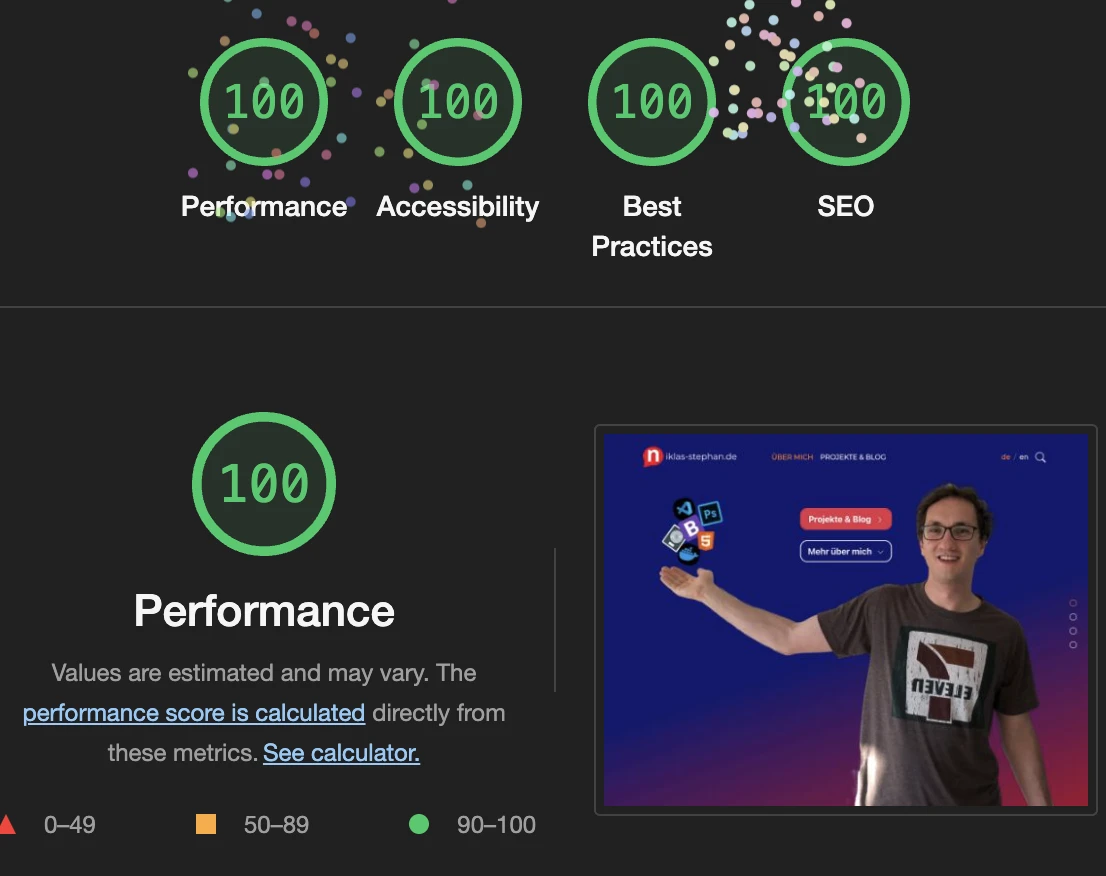
- Frontend: Durch den Verzicht auf JavaScript Frameworks und der Einfachheit des Systems an sich, werden wir mit sauberen HTML Code bei der Ausspielung belohnt. Für https://niklas-stephan.de habe ich zwar für das Frontend UI auf das HTML5 Grundgerüst von Bootstrap 5 zurück gegriffen, aber das fällt nicht mehr schwer ins Gewicht, und kommt mittlerweile im Standard ebenfalls ohne das aufgeblähte jQuery Framework zurecht.
Einfach
- Backend: Assets, Medien, Templates und Snippets werden über Visual Studio Code oder einen anderen Texteditor + Dateimanager bereitgestellt. In Node-Red wird das alles zusammengefügt, durch JavaScript Code und node.js Module um Funktionalitäten erweitert und das Endergebnis schließlich in Form von statischen Dateien in ein Verzeichnis auf einem nginx webserver zur Verfügung gestellt. Das ist der Kern von nCMS.
- Frontend: Die Wahl zwischen Deutsch und Englisch erfolgt entweder automatisch oder wird manuell festegelegt. Es gibt eine Startseite, eine Seite zu Suche, eine Seite zu Datenschutz und Impressum, eine Seite zum abfangen ungültiger Aufrufe und eine Seite mit der Übersicht über alle Posts. Selsbstredend ist das komplette UI auf alle Endgerätearten zur Darstellung optimiert.
Hinter den Kulissen
Der komplette Aufbau von nCMS erfolgt in einer Docker-Compose Umgebung.
Alle Dateien aus dem Volume src liegen ebenfalls auf https://github.com/handtrixx/ncms.
Hier meine Beispielkonfiguration auf Basis des offiziellen Node-Red Images von Docker Hub (https://hub.docker.com/r/nodered/node-red):
version: "3.0"
services:
ncms:
container_name: ncms
hostname: ncms
image: nodered/node-red:latest
restart: always
environment:
- TZ=Europe/Berlin
networks:
- dmz
logging:
options:
max-size: "10m"
max-file: "3"
volumes:
- ./data:/data
- ./dist:/dist:rw
- ./src:/src:rw
- /etc/localtime:/etc/localtime:ro
networks:
dmz:
external: trueErkärungsbedürftig sind hier eigentlich nur die Netzwerkonfiguration und die verschiedenen Volumes.
Wie auch in meinen anderen Beiträgen zu Matomo, Boinc und anderen setze ich auf meinem Cloud Server einen Reverse Proxy auf Basis des Nginx Proxy Managers (https://hub.docker.com/r/jc21/nginx-proxy-manager) ein. Das Volume/Verzeichnis ./dist ist in meinem Reverse Proxy ebenfalls über ein ln -s verlinkt, so dass man keine doppelten Deployments machen muss und ein weiterer Webserver obsolet bleibt. Node-Red selbst, also das Backend ist über eine eigene Subdomain erreichbar.
Verzeichnisstruktur
Im Verzeichnis ./src befinden sich folgende Unterordner:
- assets
- css
- fonts
- img
- js
- json
- md
- posts
- media
- x
- snippets
- templates
In das Verzeichnis assets und dessen Unterordner gehören alle im Frontend wiederholt benötigten Dateien, wie z.B. css und javascript von Bootstrap 5 (https://getbootstrap.com/), aber natürlich vor allem auch eigene Stylesheets und Javascript Funktionen. Im Unterordner json legen wir unsere statischen Übersetzungschlüssel ab.
Der Ordner md enthält in seinem Unterordner posts offensichtlich alle unsere in Markup geschriebenen Posts, welche auch an ihrer Dateiendung .md erkennbar sind.
In das Verzechnis media und maximal eine Unterodnerebene tiefer können wir alle Bilder “werfen” die wir in unseren Posts verwenden wollen. Diese werden dann während des Deployments automatisch ins platzsparende .webp Format konvertiert und ein Thumbnail für jedes Bild generiert.
Im Ordner snippteshaben wir alle HTML Elemente die wir auf allen Seiten immer wieder benötigen gelegt.
Analog dazu liegen im Verzeichnis templates die Ausgangsdateien unseres Frontends, die während des Deployments mit Inhalt angereichtert werden.
All das lässt sich Transparent auch im Github Projekt unter: https://github.com/handtrixx/ncms nachvollziehen.
Templates
Im Verzeichnis Templates befinden sich folgende Dateien: 404.html – Die Fehlerseite die immer dann angezeigt wird, wenn eine ungültige Abfrage auf die Website erfolgt. blog.html – Die Seite die die Übersicht über alle Posts bereit stellt. index.html – Die Startseite mit ihren Inhalten. post.html – Die Vorlage aus der die einzelen Beitragsseiten gerendert werden. privacy-policy.html – Die Seite zu Datenschutz und im Impressum auf die im Footer verllinkt ist und die somit von überall aus erreichbar ist und sein muss. robots.txt – Infos für die Crawler von Suchmaschinen. search.html – Meine Seite auf der man Suchen kann und die über einen json Index sämtliche Suchergebnisse ohne Abfrage am Server bereitstellt.
Snippets
Die Snippets die später im Deployment in alle HTML Templates eingeschläust werden sind footer.html, head.html, navbar.html, script.html . Durch die Aufteilung in diese Snippets haben wir den massiven Vorteil, dass wir im Falle einer gewünschten Anpassung z.B. im Navigationsmenü, diese nur genau einmal durchführen müssen um sie auf allen Seiten zu ändern.
Programmlogik mit node.js und Node-Red
Node-Red basiert auf node.js und erlaubt uns in einer Art Ablaufdiagramm verschiedene Elemente und Funktionen miteinander zu verbinden. Das nennt sich in Node-Red “Flow”. In NCMS nutze ich auch nur diese Basisfunktionalität von Node-Red und keine weitere Plug-Ins aus der Palette. Stattdessen lade ich in den verschiedenen Nodes node.js Pakete nach um den Funktionsumfang des Systems zu erweitern.
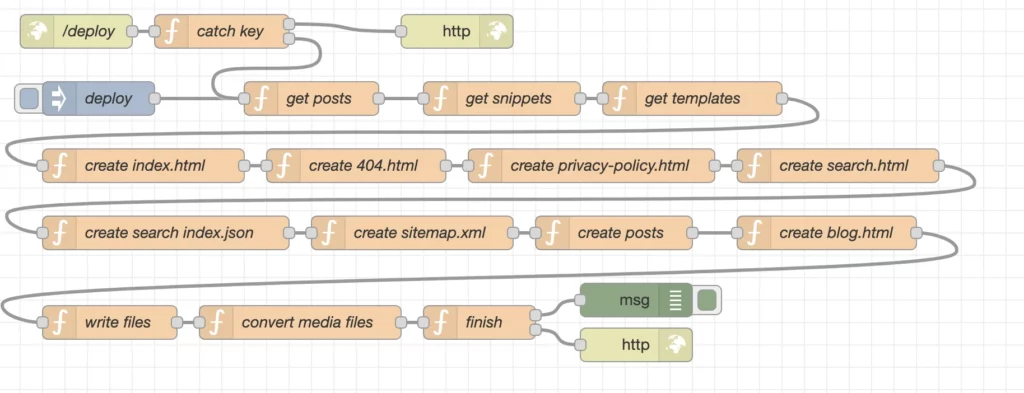
Im folgenden eine Erläuterung zu den einzelen Nodes.
/deploy
Hierbei handelt sich um einen lauschenden http in Node, um den Start eines Deplyoments durch einen Webhook zu starten. D.h. z.B. durch curl -X POST -d 'key=----' https://ncms.niklas-stephan.de/deploy startet man das Deployment.
catch key
Natürlich soll nicht einfach jeder ein Deployment starten können, deshalb noch eine kleine Sicherheitsabfrage im catch key Node.
Im Node unter “Setup” wird das npm Modul fs-extra geladen und als fse bereit gestellt, damit wir Zugriff auf das Dateisystem haben und den im Ordner /data hinterlegten key mit dem vergleichen können, der uns für das Deployment im Webhook zur Verfügung gestellt wurde.
Die Funktion selbst sieht dann so aus:
const transferedKey = msg.payload.key;
const systemKey = fse.readFileSync('/data/deploy.key', 'utf8')
if (transferedKey == systemKey) {
msg.payload = "Deployment Started";
msg.statusCode = 200;
msg.type = "webhook";
msg.starttime = Date.now();
return [null,msg];
} else {
msg.payload = "Wrong authentication!"
msg.statusCode = 400;
return [msg,null];
}Auch hat dieser Node 2 Ausgänge. Falls die beiden keys übereinstimmen wird mit dem Deployment fortgefahren – Ausgang 2. Falls aber nicht, dann wird eine Fehlernachricht an Ausgang 1 übergeben und das Deployment damit abgebrochen.
deploy
Startet das Deployment ebenfalls, aber eben manuell über die Node-Red Oberfläche und nicht als Webhook.
get posts
In diesem Node laden wir den Inhalt aller Posts aus den *.md Dateien und speichern diesen als Objekte in einem Array zu späteren Verwendung ab. Außerdem machen wir neben dem fs-extra Modul noch intensiven Gebrauch des Moduls markdown-it und Plugins für diesen. markdown-it (https://github.com/markdown-it/markdown-it) hilft uns dabei den Inhalt von Markup nach HTML zu konvertieren.
msg.baseurl = "https://niklas-stephan.de"
msg.dist = {};
msg.posts = [];
const path = '/src/md/posts/';
const postfiles = fse.readdirSync(path)
const alength = postfiles.length;
for (var i=0; i<alength; i++) {
var srcFile = path+postfiles[i];
var distFilename = postfiles[i].split('.')[0]+".html";
var srcContent = fse.readFileSync(srcFile, 'utf8')
var md = new markdownIt({
html: true,linkify: true,typographer: true,breaks: true})
.use(markdownItFrontMatter, function(metainfo) {meta = JSON.parse(metainfo);})
.use(markdownItLinkifyImages, {target: '_blank',linkClass: 'custom-link-class',imgClass: 'custom-img-class'})
.use(markdownItLinkAttributes, { attrs: {target: "_blank",rel: "noopener",}
});
distContent = md.render(srcContent);
let data = {"srcFile":""+srcFile+"","srcContent":""+srcContent+"","distContent":""+distContent+"","distFilename":""+distFilename+"",...meta};
msg.posts.push(data)
}
return msg;get snippets
Über das npm Modul fs-extra laden wir den Inhalt unserer snippets und speichern diese als Array msg.snippets, damit wir später im Flow darauf zugreifen können.
msg.snippets = {};
const path = '/src/snippets/';
const files = fse.readdirSync(path)
const alength = files.length;
for (var i=0; i<alength; i++) {
var srcFile = path+files[i];
var srcContent = fse.readFileSync(srcFile, 'utf8')
msg.snippets[files[i]] = srcContent;
}
return msg;get templates
Genauso wie die Snippets speichern wir auch den Inhalt der Templates in unserem Flow zur späteren Verwendung.
msg.templates = {};
const path = '/src/templates/';
const files = fse.readdirSync(path)
const alength = files.length;
for (var i=0; i<alength; i++) {
var srcFile = path+files[i];
var srcContent = fse.readFileSync(srcFile, 'utf8')
msg.templates[files[i]] = srcContent;
}
return msg;create index.html
Nun fangen wir an die Inhalte der einzelnen Dateien zu generieren, den Start macht unsere index.html Datei.
Die obere Hälfte des Codes betrifft das generieren der Meta Tags für Social Media und Suchmaschinen.
Im zweiten Block fügen wir in die Platzhalter des Templates die Werte Snippets, den Seitentitel, sowie die Metadaten ein.
Letztlich steht unsere fertige index.html als Objekt msg.dist.index in unserem Flow bereit um später als Datei geschrieben zu werden.
msg.dist.index = "";
var ogmetalang = "de_DE";
var ogmeta = `
<meta property="og:type" content="website">
<meta property="og:locale" content="`+ogmetalang+`">
<meta property="og:site_name" content="niklas-stephan.de">
<link rel="canonical" href="`+msg.baseurl+`/index.html">
<meta name="description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta property="og:title" content="Projects & Blog - niklas-stephan.de">
<meta property="og:description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta property="og:url" content="`+msg.baseurl+`/index.html">
<meta property="og:image" content="`+msg.baseurl+`/assets/img/me_logo.webp">
<meta property="og:image:secure_url" content="`+msg.baseurl+`/assets/img/me_logo.webp">
<meta name="twitter:card" content="summary">
<meta name="twitter:description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta name="twitter:title" content="Projects & Blog - niklas-stephan.de">
<meta name="twitter:image" content="`+msg.baseurl+`/assets/img/me_logo.webp">`
msg.dist.index = msg.templates["index.html"].replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
msg.dist.index = msg.dist.index.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
msg.dist.index = msg.dist.index.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
msg.dist.index = msg.dist.index.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
msg.dist.index = msg.dist.index.replace("<!-- PAGE TITLE -->","Home");
msg.dist.index = msg.dist.index.replace("<!-- meta tags -->",ogmeta);
return msg;create 404.html
msg.dist.errorpage = "";
msg.dist.errorpage = msg.templates["404.html"].replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
msg.dist.errorpage = msg.dist.errorpage.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
msg.dist.errorpage = msg.dist.errorpage.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
msg.dist.errorpage = msg.dist.errorpage.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
msg.dist.errorpage = msg.dist.errorpage.replace("<!-- PAGE TITLE -->","Page not found");
return msg;Die 404.htmlist schnell zusammen gebaut. wir fügen alle Snippets in unser Template ein und geben der Seite einen Namen.
Abschließend steht unser Objekt als msg.dist.errorpage zur Verfügung.
create privacy-policy.html
Genauso ein “Low-Brainer” ist die Seite mit Datenschutz und Impressum und schnell als msg.dist.privacy aufbereitet.
msg.dist.privacy = "";
msg.dist.privacy = msg.templates["privacy-policy.html"].replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
msg.dist.privacy = msg.dist.privacy.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
msg.dist.privacy = msg.dist.privacy.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
msg.dist.privacy = msg.dist.privacy.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
msg.dist.privacy = msg.dist.privacy.replace("<!-- PAGE TITLE -->","Datenschutz & Impressum");
return msg;create search.html
Bevor es wieder ein wenig komplizierter wird, zunächst noch die einfach Erzeugung des Objekts msg.dist.searchindex zur späteren Verwendung.
msg.dist.search = "";
msg.dist.search = msg.templates["search.html"].replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
msg.dist.search = msg.dist.search.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
msg.dist.search = msg.dist.search.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
msg.dist.search = msg.dist.search.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
msg.dist.search = msg.dist.search.replace("<!-- PAGE TITLE -->","Suche");
return msg;create search index.json
Um den Suchindex aufzubauen, der später eine Suche ermöglicht ohne eine Abfrage an den Server zu stellen, verwenden ich eine for Schleife die durch alle Elemente im Array msg.posts läuft und für jeden Beitrag einen Eintrag im Index als JSON Objekt erzeugt. Letztlich wird der Index als Objekt msg.dist.searchindex bereit gestellt.
var alength = msg.posts.length;
var index = "[";
for (var i=0; i<alength; i++) {
index = index+`{"lang":"`+msg.posts[i].language+`","link":"/posts/`+msg.posts[i].distFilename+`","headline":"`+msg.posts[i].title+`","content":"`+msg.posts[i].distContent.replace(/[^a-zA-Z0-9]/g, ' ')+`"},`;
}
index = index.slice(0, -1);
index = index+"]";
msg.dist.searchindex = index;
return msg;create sitemap.xml
Bei der Erzeugung der Sitemap gehen wir ähnlich vor wie beim Suchindex. Anstelle einer klassischen for Schleife verwende ich die Javascript forEach() Funktion, die im Endeffekt das gleiche bewirkt, nur etwas moderner ist.
var xml = `<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.sitemaps.org/schemas/sitemap/0.9 http://www.sitemaps.org/schemas/sitemap/0.9/sitemap.xsd">
<url>
<loc>`+msg.baseurl+`/</loc>
<priority>1.00</priority>
</url>
<url>
<loc>`+msg.baseurl+`/index.html</loc>
<priority>0.80</priority>
</url>
<url>
<loc>`+msg.baseurl+`/blog.html</loc>
<priority>0.80</priority>
</url>`
msg.posts.forEach(postxml);
xml = xml + `
</urlset>`
msg.dist.sitemap = xml;
return msg;
function postxml(item) {
if (item.published == true ) {
xml = xml + `
<url>
<loc>`+msg.baseurl+`/posts/`+item.distFilename+`.html</loc>
<priority>0.64</priority>
</url>`
}
}create posts
Wir haben zur im get posts Node bereits den Inhalt der einzelnen Posts im Array msg.posts konvertiert und bereit gestellt. Jetzt wollen wir dies noch dahingehend finalisieren, dass wir analog zu den zuvor erzeugten Dateien auch für jeden Post eine einzelne Datei erzeugen können und lege diese wiederum als Objekt im Objekt msg.dist.posts ab.
msg.dist.posts = {};
var alength = msg.posts.length;
var data = "";
var ogmetalang = "";
var ogmeta = "";
var postdate = "";
for (var i=0; i<alength; i++) {
if (msg.posts[i].language == "de") {
ogmetalang = "de_DE"
} else {
ogmetalang = "en_US"
}
img = msg.posts[i].imgurl.split('.')[0]+".webp";
ogmeta = `
<meta property="og:type" content="website">
<meta property="og:locale" content="`+ogmetalang+`">
<meta property="og:site_name" content="niklas-stephan.de">
<link rel="canonical" href="`+msg.baseurl+`/posts/`+msg.posts[i].language+`/`+msg.posts[i].distFilename+`">
<meta name="description" content="`+msg.posts[i].excerpt+`">
<meta property="og:title" content="`+msg.posts[i].title+`">
<meta property="og:description" content="`+msg.posts[i].excerpt+`">
<meta property="og:url" content="`+msg.baseurl+`/posts/`+msg.posts[i].language+`/`+msg.posts[i].distFilename+`">
<meta property="og:image" content="`+msg.baseurl+`/media/full/`+img+`">
<meta property="og:image:secure_url" content="`+msg.baseurl+`/media/full/`+img+`">
<meta name="twitter:card" content="summary">
<meta name="twitter:description" content="`+msg.posts[i].excerpt+`">
<meta name="twitter:title" content="`+msg.posts[i].title+`">
<meta name="twitter:image" content="`+msg.baseurl+`/media/full/`+img+`">`
postdate = '<small class="c-gray pb-3" id="postdate">'+msg.posts[i].date+'</small>';
data = "";
data = msg.templates["post.html"];
data = data.replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
data = data.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
data = data.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
data = data.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
data = data.replace("<!-- mardown content from posts -->",msg.posts[i].distContent);
data = data.replace("<!-- Post Headline -->", msg.posts[i].title);
data = data.replace("<!-- postdate -->", postdate);
data = data.replace("<!-- Post Image -->", '<img src="/media/thumb/'+img+'" class="img-fluid mb-2" alt="postImage">');
data = data.replace("<!-- PAGE TITLE -->",msg.posts[i].title);
data = data.replace("<!-- meta tags -->",ogmeta);
msg.dist.posts[msg.posts[i].distFilename] = data;
}
return msg;create blog.html
Nun unser letzter vorbereitender Streich, die Erzeungung der Übersicht aller Posts im Objekt msg.dist.blog.
Es ist am Umfang der Funktion ersichtlich, dass hier etwas mehr als bei den anderen Dateien passiert.
Zuerst sammeln wir alle definierten Kategorien aus den einzelnen Posts über eine for Schleife ein um dann doppelt vorhandene Werte wieder aus dem erzeugtem Array zu löschen. Das brauchen wir damit die Besucher unserer Website später über Kategorien filtern können. Jede Kategorie bekommt außerdem eine eindeutige Farbe, die einer CSS Klasse in unserem Stylesheet entspricht, zugeordnet.
Als nächstes extrahieren wir aus den Metadaten der Posts noch Titel, Kurzbeschreibung, Datum und Bild. Während dieser for-Schleife verhindert eine if-Bedingung, dass wir unveröffentliche Posts zur Auswahl aufbereiten.
Abschließend erzeugen wir aus den ermittelten Werten den entsprechenden HTML Code, fügen die Daten der Snippets ein, ergänzen die Meta Informationen zur Seite und schreiben das Ganze in das Objekt msg.dist.blog.
//get categories from all posts and extract unique ones
var categories = [];
for (var i=0 ; i<msg.posts.length;i++) {
if (msg.posts[i].published == true) {
for (var j = 0; j < msg.posts[i].keywords.length; j++) {
categories.push(msg.posts[i].keywords[j]);
}
}
}
var uniqueCategories = [...new Set(categories)];
// define a color to stick for each category
const colorcat = {};
var catcolors = ["green", "red", "blue", "orange", "yellow", "pink", "purple","indigo"];
var c=0;
for (const key of uniqueCategories) {
colorcat[key] = catcolors[c];
c = c+1;
}
//generate and set html for categorie selection
var cathtml = "";
for (var k = 0; k < uniqueCategories.length; k++) {
cathtml = cathtml + `<button data-filter=".cat-`+uniqueCategories[k]+`" type="button"
onclick="sort()" class="btn bg-` + catcolors[k] + ` c-white me-2">` + uniqueCategories[k]+`</button>`;
}
msg.dist.blog = msg.templates["blog.html"].replace("<!-- CATEGORIES -->", cathtml);
// get card content from all posts and generate html
var posthtml = "";
for (var l = 0; l < msg.posts.length; l++) {
if (msg.posts[l].published == true) {
var link = msg.posts[l].filename.slice(0, -3)+".html";
//get color for current post
var postcolor = "";
for (const key in colorcat) {
if (key == msg.posts[l].keywords[0]) {
postcolor = colorcat[key];
}
}
imgurl = msg.posts[l].imgurl.split('.')[0]+".webp";
posthtml = posthtml + `
<div class="col-sm-6 col-lg-4 my-4 filterDiv cat-`+msg.posts[l].keywords[0]+` lang-`+ msg.posts[l].language + `">
<span class="date hidden d-none">`+ msg.posts[l].date + `</span>
<span class="name hidden d-none">`+ msg.posts[l].title + `</span>
<div onclick="goto('`+ link+ `','blog')" class="card h-100 d-flex align-items-center bo-`+postcolor+`">
<div class="card-header bg-`+ postcolor + `">` + msg.posts[l].keywords[0] + `</div>
<div class="card-img-wrapper d-flex align-items-center">
<img src="media/thumb/`+ imgurl + `"
class="card-img-top" alt="iot">
</div>
<div class="card-body">
<h5 class="card-title">`+ msg.posts[l].title + `</h5>
<p class="card-text">
`+ msg.posts[l].excerpt + `
</p>
</div>
<div class="card-footer small text-center c-gray pdate">
`+msg.posts[l].date+`
</div>
</div>
</div>
`;
}
}
msg.dist.blog = msg.dist.blog.replace("<!-- POSTS -->", posthtml);
var ogmetalang = "de_DE";
var ogmeta = `
<meta property="og:type" content="website">
<meta property="og:locale" content="`+ogmetalang+`">
<meta property="og:site_name" content="niklas-stephan.de">
<link rel="canonical" href="`+msg.baseurl+`/blog.html">
<meta name="description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta property="og:title" content="Projects & Blog - niklas-stephan.de">
<meta property="og:description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta property="og:url" content="`+msg.baseurl+`/blog.html">
<meta property="og:image" content="`+msg.baseurl+`/assets/img/me_logo.webp">
<meta property="og:image:secure_url" content="`+msg.baseurl+`/assets/img/me_logo.webp">
<meta name="twitter:card" content="summary">
<meta name="twitter:description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta name="twitter:title" content="Projects & Blog - niklas-stephan.de">
<meta name="twitter:image" content="`+msg.baseurl+`/assets/img/me_logo.webp">`
msg.dist.blog = msg.dist.blog.replace("<!-- meta tags -->",ogmeta);
msg.dist.blog = msg.dist.blog.replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
msg.dist.blog = msg.dist.blog.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
msg.dist.blog = msg.dist.blog.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
msg.dist.blog = msg.dist.blog.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
msg.dist.blog = msg.dist.blog.replace("<!-- PAGE TITLE -->","Projekte & Blog");
return msg;write files
Jetzt wollen wir endlich unsere mühevoll erzeugten Objekte in msg.dist als reale Dateien festschreiben.
In unserer Funktion “write files” binden wir dafür wieder das npm modul fs-extra als fse ein.
Alle erzeugten Dateien sollem im Verzeichnis /dist/ landen. Gleichzeitig wollen wir auch alle spuren vorheriger Deployments löschen, damit uns “Dateileichen” und ähnliche nicht zu Inkonsitenzen führen.
Das den fse Funktionen vorangestellte await stellt eine sequentielle Ausführung der einzelnen Schritte sicher, in dem es wartet bis der jeweilige Aufruf auch komplett abgeschlossen ist.
Also wird in der Funktion im ersten Schritt das Verzeichnes /dist komplett geleert und dann alle benötigten Unterordner wieder leer erstellt.
Als nächstes kopieren wir unsere Assets von /src/assets/ nach /dist/assets/ und machen das Gleiche mit der robots.txt Datei.
Anschließend schreiben wir die Inhalte der Objekte in msg.dist in die jeweilige Datei fest, um dann in einer Schleife durch alle Posts zu gehen und diese ebenfalls in das Dateisystem zu schreiben.
await fse.emptyDir('/dist').then(() => {
fse.mkdirSync('/dist/media');
fse.mkdirSync('/dist/media/full');
fse.mkdirSync('/dist/media/thumb');
fse.mkdirSync('/dist/posts');
});
await fse.copySync('/src/assets/', '/dist/assets/');
await fse.copySync('/src/templates/robots.txt', '/dist/robots.txt');
await fse.writeFileSync('/dist/index.html', msg.dist.index);
await fse.writeFileSync('/dist/blog.html', msg.dist.blog);
await fse.writeFileSync('/dist/404.html', msg.dist.errorpage);
await fse.writeFileSync('/dist/privacy-policy.html', msg.dist.privacy);
await fse.writeFileSync('/dist/search.html', msg.dist.search);
await fse.writeFileSync('/dist/sitemap.xml', msg.dist.sitemap);
await fse.writeFileSync('/dist/searchindex.json', msg.dist.searchindex);
const postfilefolder = "/dist/posts/"
await Object.entries(msg.dist.posts).forEach(item => {
var [key, value] = item;
fse.writeFileSync(postfilefolder+key, value)
});
return msg;convert media files
Noch etwas komplexer ist die Erzeugung der Mediendatein. Die Dateien aus dem Verzeichnis /src/media/und einer Unterordnerebene tiefer, wollen wir ins Speicher sparende .webp Format konvertieren und zusätzlichen jeweils einen Thumbnail in geringerer Auflösung generieren. Außerdem wollen wir das nur Medien mit den Quellformaten .jpg, .jpeg, .png oder .gif konvertiert werden. Alle anderen Dateien werden ohne Änderung direkt nach /dist/media/full/ kopiert. Um uns die Arbeit zu erleichten greifen wir auf die npm Module fs-extra als fse und sharp zurück.
Man beachte auch, das ich das await Kommando bewusst bei der Erzeugung der Dateien ausspare, so dass die Schleifen bereits mit der nächsten Datei aus ihren Arrays starten, bevor die Schreiboperation abgeschlossen ist. Das beschleunigt das Deployment um einen sehr großen Faktor, bei dem geringen Risiko bzw. dem akzeptieren Umstand, dass eine Mediendatei noch nicht geschrieben/verfügbar ist, wenn das Deplyoment abgeschlossen ist.
var srcpath = '/src/media/';
var fullpath = '/dist/media/full/';
var thumbpath = '/dist/media/thumb/';
const filetypes = ["jpg", "jpeg", "png", "gif", "webp"];
const mediafiles = fse.readdirSync(srcpath);
const alength = mediafiles.length;
var mediafile = "";
var targetfile = "";
for (var i=0; i<alength; i++) {
mediafile = mediafiles[i];
if (mediafile.includes(".")) {
targetfile = mediafile.split('.')[0];
if (filetypes.includes(mediafile.split('.')[1]) ) {
sharp(srcpath+mediafile)
.toFile(fullpath+targetfile+'.webp');
sharp(srcpath+mediafile).resize({ width: 440 })
.toFile(thumbpath+targetfile+'.webp');
} else {
fse.copySync(srcpath+mediafile, fullpath+mediafile)
}
} else {
var subsrcpath = srcpath+mediafile+"/";
var subfullpath = fullpath+mediafile+"/";
var subthumbpath = thumbpath+mediafile+"/";
var submediafiles = fse.readdirSync(subsrcpath);
var blength = submediafiles.length;
await fse.mkdirSync(subfullpath);
await fse.mkdirSync(subthumbpath);
for (var j=0; j<blength; j++) {
submediafile = submediafiles[j];
subtargetfile = submediafile.split('.')[0];
if (filetypes.includes(submediafile.split('.')[1]) ) {
sharp(subsrcpath+submediafile)
.toFile(subfullpath+subtargetfile+'.webp');
sharp(subsrcpath+submediafile).resize({ width: 440 })
.toFile(subthumbpath+subtargetfile+'.webp');
} else {
fse.copySync(subsrcpath+submediafile, subfullpath+submediafile)
}
}
}
}
return msg;finish
Unser Deployment nähert sich dem Ende. Wir errechnen noch die Dauer des Deployments und setzen einen Zeitstempel um diese Informationen in der Datei /dist/deploy.log festzuhalten. Die Datei wird dann wieder mit dem npm Modul fs-extra als fse geschrieben. Je nach Auslöser des Depyloyments, also manuell vs. webhook, wird dann abschließnd an ein Debug Node oder an den Debug Node und einen http-out Node weitergeleitet.
var endtime = Date.now();
var duration = endtime-msg.starttime;
duration = duration;
let yourDate = new Date()
var depdate = yourDate.toISOString();
var log = "Deployment duration: "+duration+" ms \n";
log = log+"Deployment timestamp: "+depdate;
msg.statusCode = 200;
fse.writeFileSync('/dist/deploy.log', log);
msg.payload = log;
if (msg.type != "manual") {
return [msg,msg];
} else {
return [msg,null];
}msg & http
Fertig! Die Beiden Nodes msg und http dienen zum sauberen Abschluss unseres Deployments.
Der “http out” Node liefert den zuvor definierten Body als Nachricht zurück an den aufrufenden Webhook.

Der “msg” Debug Node zeigt uns den kompletten Inhalt des Deployments im Debugger von Node-Red an, wenn aktiviert.
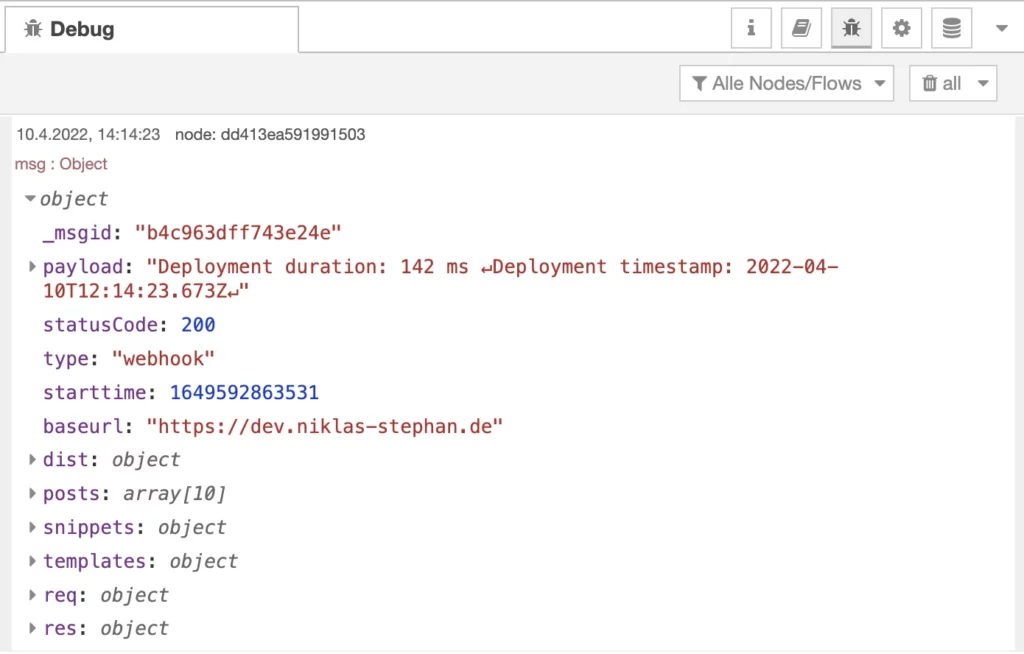
Den kompletten Node-Red Flow könnt ihr euch auch hier herunterladen https://niklas-stephan.de/media/orig/ncms/flow.json (Version 0.60).
Fazit
Zugegeben, hätte ich eine Stoppuhr genutzt um aufzuzeichnen wie lange die Entwicklung von nCMS gedauert hat, vielleicht hätte ich irgendwann abgebrochen. Aber: von Start bis Ende des Projekts, ganz wie bei einem rundenbasierten Strategiespiel, war regelmäßig der “nur diese eine Sache noch” Moment da. Eine Menge Spaß hat es außerdem gemacht, mit Hilfe von Node-Red immer ausgefeiltere JavaScript Funktionen zu entwickeln. Der fest integrierte Debugger war dabei eine fast genauso große Hilfe, wie die Möglichkeit in Node-Red javascript Funktionen maximal einfach auf weitere node.js Module zuzugreifen. Falls ihr mal eine ähnliches Vorhaben umsetzen möchtet, könnt ihr gerne meine Quellen Auf Github forken.
Einige verbesserungswürdige Schwachstellen gibt es natürlich auch noch.
Zum Beispiel an den Stellen, bei denen ich im Node-Red Backend auf das Frontend referenziere. Das macht das Ganze etwas weniger flexibel, denn wenn wirklich mal jemand meine Quellen nutzen möchte, müsste sie/er sich entsprechend noch in das Frontend einarbeiten.
Und überhaupt bin ich hier im Artikel nicht auf das HTML5 Frontend mit javascript Funktionen, CSS und HTML weiter eingegangen.
Vielleicht folgt das ein andernmal.
Quellen / Weiterführende Links
Hier nochmal alle Quellen, Links und Dateien aus dem Artikel zusammen aufgeführt:
- Die Quellen von NCMS bei Github: https://github.com/handtrixx/ncms
- Der Node-Red Flow von NCMS: https://niklas-stephan.de/media/full/ncms/ncms_flow.json
- Das fantastastische Node-Red: https://nodered.org/
- Node-Red als Container bei Docker Hub: https://hub.docker.com/r/nodered/node-red
- Ngnix Proxy Manager: https://nginxproxymanager.com/
- Das famose Bootstrap HTML5 Template von Twitter: https://getbootstrap.com/
- markdown-it – von Markup nach HTML in einfach: https://markdown-it.github.io/
- Dateisystemoperation in node.js mit fs-extra: https://github.com/jprichardson/node-fs-extra
- Rasend schnelle Konvertierung von Bildern in node.js mit sharp: https://sharp.pixelplumbing.com/