Brauchen wir 2023 wirklich noch eine spezielle Lösung für das Backup unseres Rechners? Wir haben doch iCloud/OneDrive/…! – Korrekt, aber dabei handelt es sich um Dateisynchronisation und nicht um Backups! Den Unterschied und wie man mit Hilfe eines Raspberry Pi oder ähnlichem mit Docker Compose eine Backup Lösung für seinen Mac aufsetzt, die der original Apple TimeMachine in nichts nachsteht, erkläre ich in diesem Post.
Grundbegriffe, Backup vs. Synchronisation
Mit der sogenannten TimeMachine hatte Apple es wieder einmal geschafft, einen Service der bei anderen wahnsinnig kompliziert einzurichten ist/war, kinderleicht bedienbar zu machen. Leider scheinen Datensicherungen in das lokale Netz aus der Mode gekommen zu sein, so propagiert Apple selbst nur noch das Backup direkt auf einen USB-Speicher oder eben in die eigene iCloud. Dabei haben beide Lösungen größere Nachteile. Für das lokale Backup muss ich immer daran denken, das externe Speichermedium in den Rechner zu stecken und kommt es z.B. zu einem Kurzschluss während beide Geräte miteinander verbunden sind, sind auch beide zerstört. Dahin ist die Datensicherung, genau dann wenn man sie am meisten braucht. Die Alternativen iCloud und Co. begleiten ebenfalls mehrere Nachteile. Zum einen vertrauen wir unsere Daten einem externen Anbieter an, der uns zwar versprechen kann dass diese dort sicher und geschützt aufbewahrt werden, aber garantieren kann uns das niemand. Außerdem handelt es sich bei iCloud und ähnlichen zunächst nur um Services zur Dateisynchronisation. D.h. meine Daten werden parallel lokal und eben in der Cloud abgelegt. Das heisst auch, wenn ich eine Datei lokal lösche, passiert das gleiche auch in der Cloud. Und wieder Adieu liebe Dateischerung. Dem entgegen wirk die Dateiversionierung die entweder Standardmäßig oder optional aktiviert werden kann, allerdings habe ich selbst die Erfahrung gemacht, dass diese auch genau dann wenn man sie bräuchte gerade mal nicht funktioniert.
Aus diesen und anderen Gründen hat Apple noch ein „Türchen“ offen gelassen und stellt es anderen Herstelleren z.B. von Netzwerkspeichern wie QNAP frei, TimeMachine in ihre Hardwarelsöungen einzubinden, auch wenn Apple selbst keine entsprechende Hardware mehr vertreibt.
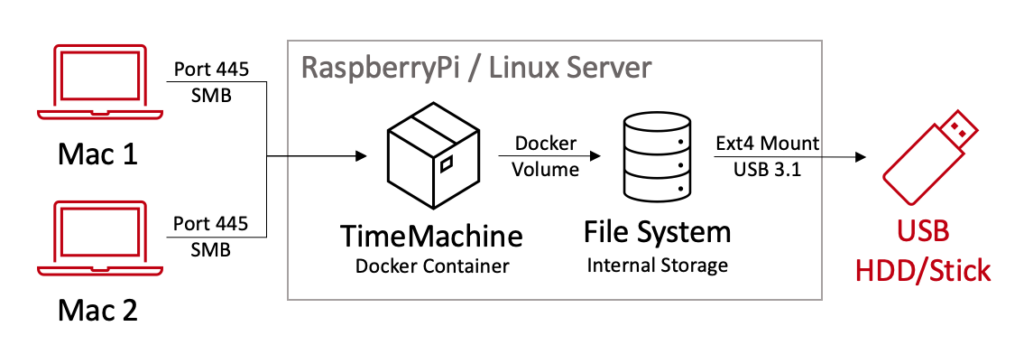
Falls ihr aber so wie ich sowieso schon einen Linux Server oder RaspberryPi mit Docker Compose habt, geht es auch noch einfacher: Wir konfigurieren einfach einen Container der als TimeMachine Server im Heimnetz dient!
Server vorbereiten
Zunächst verbinden wir unseren externen Speicher, ich selbst verwende eine externe Festplatte, mit unserem Server. Falls nicht schon geschehen, formatieren wir unseren Speicher noch in einem für Linux nativen Dateisystem.
Festplatte formatieren
Um eine externe Festplatte in der Linux-Kommandozeile mit dem Dateisystem ext4 zu formatieren, kannst du die folgenden Schritte befolgen:
Schließe die externe Festplatte an deinen Computer an. Stelle sicher, dass sie erkannt wird und einen zugewiesenen Gerätepfad hat. Du kannst dies mit dem Befehl lsblk überprüfen, der eine Liste der blockbasierten Geräte anzeigt.
Öffne ein Terminal oder eine Konsole, um die Linux-Kommandozeile zu öffnen.
Gib den Befehl sudo fdisk -l ein, um eine Liste der erkannten Festplatten und ihrer Partitionen anzuzeigen. Finde den Gerätepfad deiner externen Festplatte in der Liste. Normalerweise wird sie als „/dev/sdX“ bezeichnet, wobei „X“ für einen Buchstaben steht (z. B. /dev/sdb).
Stelle sicher, dass du den richtigen Gerätepfad auswählst und die Daten auf der Festplatte sicher gesichert hast. Das Formatieren einer Festplatte löscht alle darauf befindlichen Daten unwiederbringlich.
Gib den folgenden Befehl ein, um das Festplattenformat zu ändern und das Dateisystem ext4 zu erstellen:
sudo mkfs.ext4 /dev/sdX
Ersetze „/dev/sdX“ durch den tatsächlichen Gerätepfad deiner externen Festplatte.
Der Befehl wird dich fragen, ob du fortfahren möchtest, da er alle Daten auf der Festplatte löschen wird. Bestätige mit „y“ und drücke die Eingabetaste.
Der Formatierungsvorgang beginnt und kann je nach Größe der Festplatte einige Zeit in Anspruch nehmen.
Sobald der Vorgang abgeschlossen ist, erhältst du eine Bestätigungsmeldung.
Deine externe Festplatte sollte nun erfolgreich mit dem ext4-Dateisystem formatiert sein und bereit für die Verwendung unter Linux sein.
Festplatte/Speicher dauerhaft mounten
Als nächstens wollen wir erreichen, dass der Speicher bzw. die Festplatte bei jedem Neustart des Systems automatisch „gemountet“ (an das System angehangen wird).
Um eine mit ext4 formatierte Festplatte in der /etc/fstab-Datei zu mounten, kannst du die folgenden Schritte befolgen:
Öffne ein Terminal oder eine Konsole, um die Linux-Kommandozeile zu öffnen.
Gib den Befehl sudo blkid ein, um eine Liste der erkannten Festplatten und ihrer UUIDs anzuzeigen. Finde die UUID deiner ext4-formatierten Festplatte in der Liste. Die UUID sieht in etwa so aus: UUID=xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx.
Erstelle einen Ordner, der als Mountpunkt für die Festplatte dienen soll. Du kannst dies mit dem Befehl sudo mkdir <mountpunkt> tun, wobei <mountpunkt> der Pfad zu dem gewünschten Ordner ist. Zum Beispiel:
sudo mkdir /mnt/backup
Öffne die /etc/fstab-Datei in einem Texteditor mit Root-Berechtigungen. Zum Beispiel:
sudo nano /etc/fstab
Füge eine neue Zeile am Ende der /etc/fstab-Datei hinzu, um die Festplatte zu mounten. Die Syntax lautet:
UUID=<UUID> <mountpunkt> ext4 defaults 0 2
Ersetze <UUID> durch die UUID deiner Festplatte und <mountpunkt> mit dem Pfad zum zuvor erstellten Ordner.
Speichere die Änderungen und schließe den Texteditor.
Um die Festplatte sofort zu mounten, ohne den Computer neu zu starten, gib den Befehl sudo mount -a ein. Dadurch werden die Einträge in der /etc/fstab-Datei gelesen und die entsprechenden Festplatten gemountet.
Die Festplatte wird nun jedes Mal automatisch beim Systemstart gemountet, indem die Informationen in der /etc/fstab-Datei verwendet werden. Du kannst auf die Dateien und Ordner in der Festplatte über den angegebenen Mountpunkt zugreifen.
Docker Container mit Compose einrichten
Falls ihr Docker und Docker Compose noch nicht installiert habt, ist das vorgehen hierzu hier beschrieben. Wir nutzen das Image „mbentley/timemachine“ von Docker Hub um die Funktionalität der TimeMachine so nachzustellen, wie es auch die Anbieter von professionellen Backuplösungen tun.
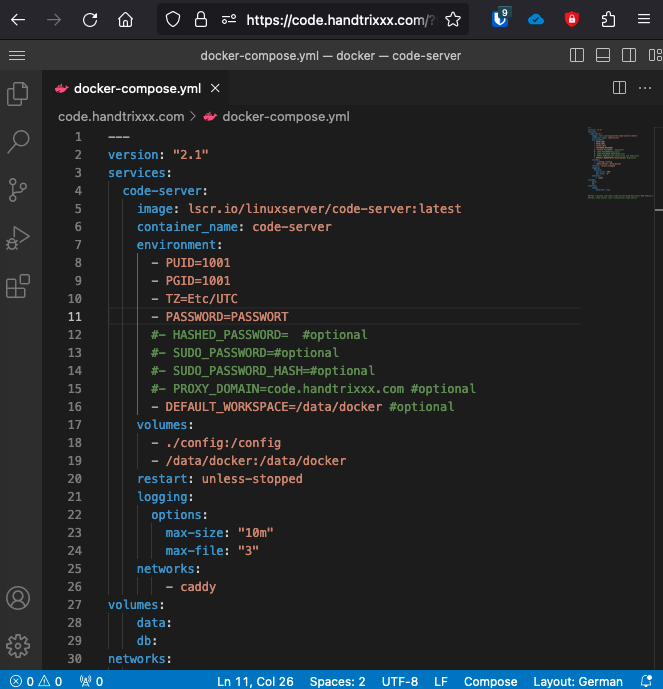
Um den Docker-Container „mbentley/timemachine:smb“ mit Docker Compose zu starten, erstelle bitte eine docker-compose.yml-Datei mit den entsprechenden Konfigurationen. Hier ist ein Beispiel, das auf dem Image basiert und einen Dienst für den Container definiert:
Speichere die Datei als docker-compose.yml. Dieses Beispiel verwendet den Port 445 für den SMB-Zugriff. Es bindet auch das Verzeichnis /mnt/backup/timemachine auf dem Host mit dem Verzeichnis /opt/timemachine im Container, so dass die Backups auf der externene Festplatte gespeichert werden.
Führe dann den folgenden Befehl aus, um den Container zu starten:
docker-compose up -d
Dadurch wird der Container im Hintergrund gestartet. Die Option -d stellt sicher, dass der Dienst im Hintergrund (detached mode) läuft.
Jetzt läuft der Container „mbentley/timemachine:smb“ und ist über die konfigurierten Ports erreichbar. Du kannst dann eine Time Machine-Verbindung zu deinem Docker-Host mit dem entsprechenden SMB-Protokoll herstellen und das Verzeichnis /mnt/backup/timemachine verwenden, um deine Backups zu speichern.
Backup auf dem Mac konfigurieren
Nun haben wir alle vorbereitenden Schritte auf unserem Server abgeschlossen und widmen uns unserem zu sicherenden Mac. Ich habe die Erfahrung gemacht, dass sich ein Backup am leichtesten einrichten lässt, wenn man sich zuvor mit dem Netzlaufwerk auf dem Server verbindet. Um dich mit einem SMB-Laufwerk auf deinem Mac zu verbinden, befolge diese Schritte:
Öffne den Finder auf deinem Mac.
Klicke in der Menüleiste auf „Gehe zu“ und wähle „Mit Server verbinden…“ (oder verwende die Tastenkombination „Cmd + K“).
Gib die Adresse des SMB-Laufwerks in das Eingabefeld ein. Die Adresse kann entweder die IP-Adresse des Servers oder sein Netzwerkname (falls verfügbar) sein. Das Format der Adresse lautet smb://<adresse>. Zum Beispiel: smb://192.168.0.100 oder smb://meinserver.
Klicke auf „Verbinden“.
Es wird ein Dialogfenster angezeigt, in dem du deine Anmeldeinformationen eingeben musst. Gib den Benutzernamen und das Passwort für den Zugriff auf das SMB-Laufwerk, so wie in der Docker Compose Datei konfiguriert, ein. Du hast auch die Möglichkeit, das Kästchen „Anmeldeinformationen im Schlüsselbund speichern“ anzukreuzen, um die Anmeldeinformationen für zukünftige Verbindungen zu speichern.
Klicke auf „Verbinden“.
Wenn die Anmeldeinformationen korrekt sind und der Zugriff gewährt wurde, wird das SMB-Laufwerk im Finder angezeigt. Du kannst nun auf die Dateien und Ordner des Laufwerks zugreifen und diese bearbeiten.
Das SMB-Laufwerk wird nach der Verbindung im Abschnitt „Freigaben“ im Finder angezeigt. Du kannst auch ein Lesezeichen für das SMB-Laufwerk erstellen, indem du es zum Finder-Sidebar ziehst. Dadurch wird der Zugriff in Zukunft vereinfacht.
Wenn du die Verbindung trennen möchtest, kannst du das SMB-Laufwerk einfach aus der Seitenleiste des Finders ziehen oder mit der rechten Maustaste auf das Laufwerk klicken und „Verbindung trennen“ auswählen.
Bitte beachte, dass für eine erfolgreiche Verbindung das SMB-Protokoll auf dem SMB-Laufwerk aktiviert sein muss und die Netzwerkeinstellungen des Macs korrekt konfiguriert sein sollten.
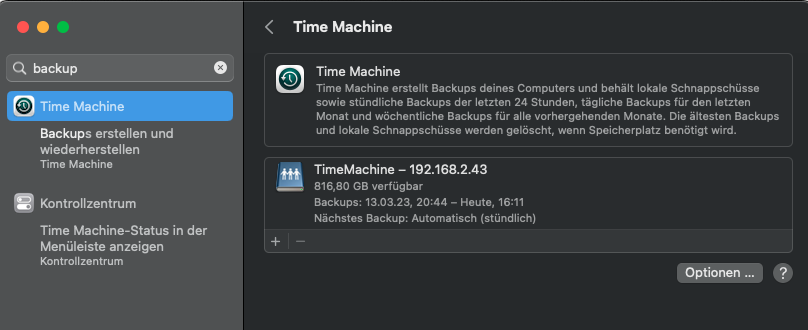
Um ein regelmäßiges Backup auf einen Netzwerkspeicher (Network Attached Storage, NAS) unter macOS einzurichten, kannst du Time Machine verwenden. Folge diesen Schritten:
Stelle sicher, dass dein Netzwerkspeicher ordnungsgemäß mit deinem Netzwerk verbunden ist und zugänglich ist.
Gehe zu „Systemeinstellungen“ auf deinem Mac und klicke auf „Time Machine“.
Klicke auf „Time Machine aktivieren“.
Klicke auf „Weitere Optionen“.
Wähle die Option „Backup-Datenträger auswählen“.
Wähle im Finder den Netzwerkspeicher aus, den du für das Backup verwenden möchtest, und klicke auf „Auswählen“.
Time Machine wird das Backup-Volume überprüfen und formatieren, falls erforderlich.
Nachdem das Volume ausgewählt wurde, kehre zu den Time Machine-Einstellungen zurück.
Aktiviere das Häkchen bei „Automatische Backups“.
Du kannst auch den Zeitplan für die Backups anpassen, indem du das Häkchen bei „Automatische Backups“ deaktivierst und dann bestimmte Zeiten festlegst, zu denen die Backups stattfinden sollen.
Du kannst außerdem die Einstellungen für „Ausgeschlossene Elemente“ anpassen, um bestimmte Ordner oder Dateien von den Backups auszuschließen.
Sobald du die oben genannten Schritte abgeschlossen hast, wird Time Machine regelmäßig automatische Backups auf deinem Netzwerkspeicher durchführen. Beachte, dass die Geschwindigkeit der Backups von der Netzwerkverbindung abhängt und möglicherweise länger dauern kann als bei einem direkt angeschlossenen Speichergerät.
Es ist auch wichtig sicherzustellen, dass der Netzwerkspeicher ordnungsgemäß konfiguriert ist und mit dem Mac kompatibel ist, um die bestmögliche Time Machine-Unterstützung zu gewährleisten. Konsultiere die Dokumentation deines NAS-Herstellers für weitere Informationen zur Einrichtung der Time Machine-Unterstützung.
Microsofts Visual Studio Code hat sich über die letzten Jahre als Quasi-Standard, nicht nur für das editieren von Quellcode in allen möglichen (Programmier-)Sprachen, sondern auch für eine Vielzahl weiterer Operationen etabliert.
Einer der Kritikpunkte bleibt die durch den Editor verursachte realtiv hohe Systemlast, die zwar begründet ist aber für einen „Texteditor“ doch etwas merkwüdig erschenint. Ein anderer Kritikpunkt ist, dass für das beliebte „Remote SSH“ Plugin, welches es ermöglicht auf einen beliebigen über SSH erreichbaren Server mit VS Code zu arbeiten, ziemlich viele dynamische Ports geöffnet werden und auch generell einige Firewalls hier Probleme machen können.
Nun basiert VS Code selbst auf dem Electron Framework, welches wiederum auf JavaScript aufbaut. Warum also nicht die VS Code Installation auf einem Server hosten und per Webinterface zur Verfügung stellen? Das haben sich offensichtlich viele gefragt und deshalb ist dies mit Hilfe von Docker und Caddy schnell bewerkstelligt.
environment – PUID Die Prozess ID die möglichst der ID eures Benutzers entsprechen sollte, damit ihr später Berechtigungsproblemen beim editieren von Dateien aus dem Wege gehen könnt. Eure eigene ID bekommt ihr einfach über die Linux Kommandozeile mit dem Befehl „id“ heraus.
environment – PGID Das Gleiche wie für die PUID, nur das hier die Gruppen ID gemeint ist.
enivronment – PASSWORD Das Passwort was abgefragt wird, wenn man die URL des containers aufruft. Da nichtmal ein User gesetzt wird, ist das nicht besonders sicher und es sollte eine zusätzliche Sicherheitsstufe z.B. über den Reverse Proxy geschaffen werden. Siehe Kapitel „Härtung“.
environment – SUDO_PASSWORD Hier lässt sich das sudo password für den Container setzen. Nach möglichkeit sollte dies vermieden werden, da man in einem Container nach Security Best Practices nie als root arbeiten sollte.
environment – HASHED_PASSWORD und SUDO_PASSWORD_HASH Beide Parameter sollen dabei helfen, dass keine Passwörter im Klartext in der „docker-compose.yml“ abgelegt werden müssen. Wie man solch einen Hash Wert generiert ist auf der Projektseite erläutert, hat aber zumindest für mich so nicht funktioniert. Auch deshalb ist eine zusätzliche „Härtung“ wie nachfolgend beschrieben erforderlich.
environment – DEFAULT_WORSPACE Hier geben wir den Pfad auf dem Container an, der nachfolgend unter Volumes spezifiert ist. Diesen sehen wir dann als Workspace/Ordner in VS Code.
volumes – /ORDNERHOST:/ORDNDERCONTAINER Wenn gewünscht können wir hier einen Pfad auf unserem Host(Server) spezifizieren der in VS Code auftaucht. Die Variable ORDNERCONTAINER ersetzen wir wiederum durch den Wert den wir als „DEFAULT_WORKSPACE“ angegeben haben.
Nun können wir den Container mit „docker compose up -d“ starten.
Härtung und Reverse Proxy Konfiguration
In unserem Caddyfile unseres Rerverse Proxy ergänzen wir einen Block für die neue VS Code Instanz. Das kann so aussehen:
code.handtrixxx.com {
basicauth {
USER HASHWERT
}
reverse_proxy code-server:8443
}
Man beachte die Werte in den geschweiften Klammern hinter „basicauth“. Diese bringen zusätzlichem Schutz vor möglichen Angreifern, in dem sie ein weitere Anmeldung bereitstellen, sobald jemand die URL öffnet. Als USER könnten ihr einen Namen euerer Wahl festlegen während man für die Generierung des Hashwerts auf der Kommandoziele in den Docker Compose Ordener von Caddy wechselt und dort folgendes Kommando ausführt:
Den aus der Abfrage resultierenden Wert kopiert ihr einfach in das Caddyfile als HASHWERT.
Nachdem wir die Konfiguration von Caddy neu geladen haben, ist VS Code unter der angegebenen URL erreichbar und die eine zusätzliche Sicherheitsschicht aktiviert.
Wir alle wissen um die Macht des Konzerns Alphabet, der hinter der Google Suchmaschine steht: Wir suchen eine bestimmte Information im Internet und ein Algorithmus entscheidet intransparent für uns, welche Ergebnisse uns präsentiert werden. Natürlich könnte man auf eine andere Suchmaschine ausweichen, aber Google ist doch so schön bequem…
In diesem Artikel beschreibe ich, wie man sich mit SearXNG selbst eine (Meta-)Suchmaschine aufsetzen kann um dem Dilemma zumindest ein Stück weit zu entkommen.
Suchmaschine, Suchindex, Meta-Suchmaschine
Das Herzstück einer jeden Suchmaschine ist ein Index, hier ein Verzeichnis aller bekannten Webseiten im Internet. Wie sich jeder vorstellen kann, ist der Aufbau eines Index für das Internet kein Leichtes unterfangen und die resultierende Datenbank gigantisch groß. Ebenso muss so ein Index ständig aktualisiert werden, damit es nicht zu toten Links in den Suchergebnissen kommt. Der Betreiber einer echte Suchmaschine muss also einen eigenen Index aufbauen und diese dazu gehörigen Aufwände stemmen. Deshalb gibt es weit weniger echte Suchmaschinen mit eigenen Index, als man vielleicht denkt. Ein Blick auf den entsprechenden Beitrag in Wikipedia offenbart uns, dass weltweit nur um die 10 Betreiber eines öffentlich Index gibt. Reduziert auf die für uns relevanten bleiben Alphabets Google, Microsofts Bing und 1-2 Exoten.
Alleine einen eigenen Suchindex aufzubauen ist allerdings auch utopisch, weshalb jetzt Meta-Suchmaschinen ins Spiel kommen. Eine Meta-Suchmaschine nimmt unseren Suchbegriff, holt sich die Ergebnisse bei verschiedenen Suchmaschinenbetreibern ab und stellt uns die Ergebnisse übersichtlich dar.
SearXNG
SearXNG ist eine Open Source Projekt das uns eine Meta-Suchmaschine für den eigenen Betrieb oder in öffentlich gehosteten Implementierungen zur Verfügung stellt. Dadurch entsteht eben nicht nur der Vorteil der weniger limitierten Suchergebnisse, sondern zusätzlich auch ein zusätzlich grad an Anonymisierung. D.h. Google oder Microsoft können die Suchabfragen weder direkt eurem Benutzer als auch nicht eurer IP-Adresse zuordnen. Dieser Effekt wird umso größer, desto mehr Menschen die jeweilige SearXNG Instanz nutzen. Bei SearXNG handelt es sich um einen sogenannten Fork (Abspaltung/Vergabelung) von SearX, der aktiv gewartet und in vielen Punkten verbessert wurde.
SearXNG in einer Docker Compose Umgebung betreiben
Jetzt wollen wir nicht länger warten und SearXNG auf unserem eigenen Server starten. Wir gehen davon aus, dass wir Docker und einen Reverse Proxy bereits installiert haben. Falls das bei euch nicht der Fall ist schaut euch zunächst die entsprechenden Anleitung an. Eine einfache Docker Compose Defintion in der „docker-compose.yml“ kann dann wie folgt aussehen:
Nach dem hochfahren erhalten wir also 2 Contianer, einen Redis Cache und den Applikationsserver von SearXNG. Entgegen der offiziellen Beispieldokumentation haben wir hier auf einen zusätzlichen Caddy Reverse Proxy verzichtet und auch keine Ports exponiert. Dafür liegt der Applikationscontainer zusätzlich im gleichen Netz (Proxy) wie unser generischer Reverse Proxy.
Fazit
Wie aus der Konfiguration hervorgehen haben wir jetzt eine laufende Installation, welche über https://search.handtrixxx.com aus dem Internet erreichbar ist. Anschließend habe ich noch die Standardsuchengine in meinen lokalen Browsern so umgestellt, dass immer meine eigene Engine verwendet wird. Leider erlaubt Apple dies auf dem iPhone/iPad nicht. Gerne könnt ihr aber ebenfalls meine Instanz verwenden und so zur weiteren Anonymisierung beitragen oder euch eben selbst an einer Installation probieren.
Nachdem ich mehrere Jahre lang sowohl Traefik, als auch den Nginx Proxy Manager als Reverse Proxy für meine Docker Container genutzt habe, bin ich nun bei Caddy angelangt. Am Nginx Proxy Manager störte mich, dass zur Konfiguration ausschließlich die Web UI zur Verfügung steht. Das hat mich in Backup/Restore Szenarien öfter an die Grenzen gebracht, was zum Schluss dazu führte jedes Mal aufs neue eine Klickorgie zu veranstalten. And Traefik störte mich wiederum die aufgeblähte Konfiguration, sowie die vielen Labels die an jedem zu berücksichtigenden Container ergänzt werden müssen. Caddy bietet mit einer CLI und einer API, die gewünschte Flexibilität und lässt sich auch einfach sichern/wiederherstellen.
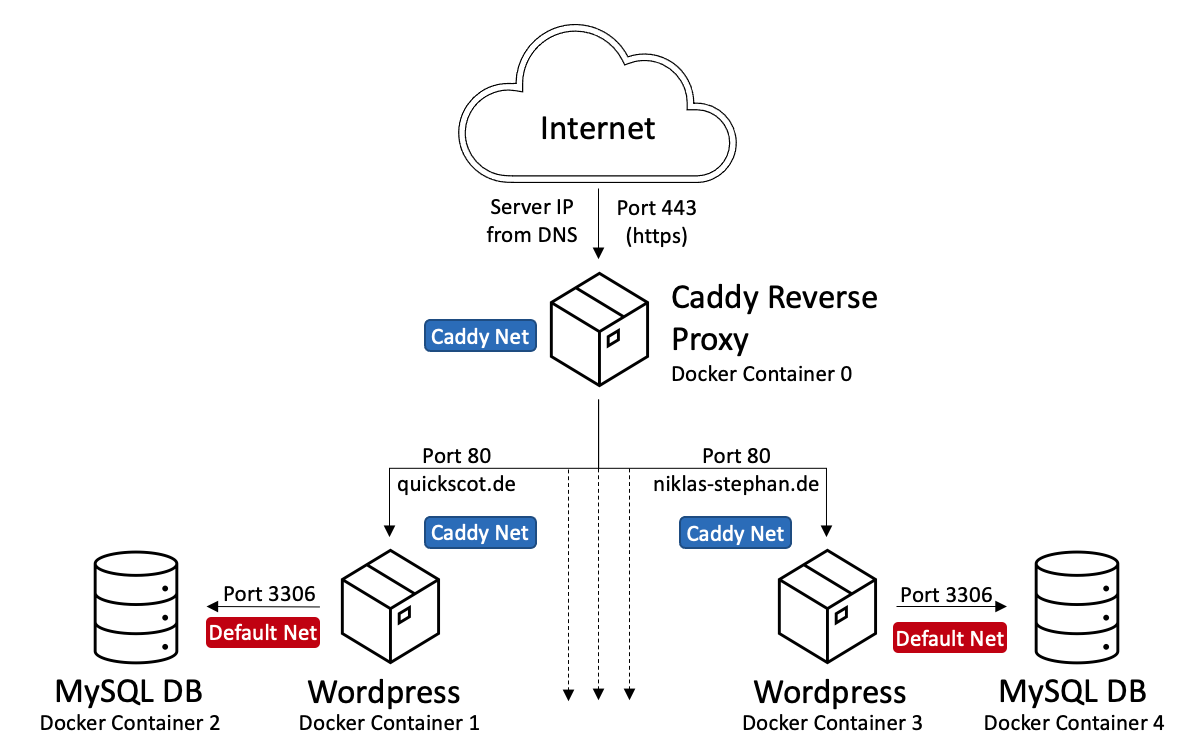
Warum eine Reverse Proxy für Docker Container?
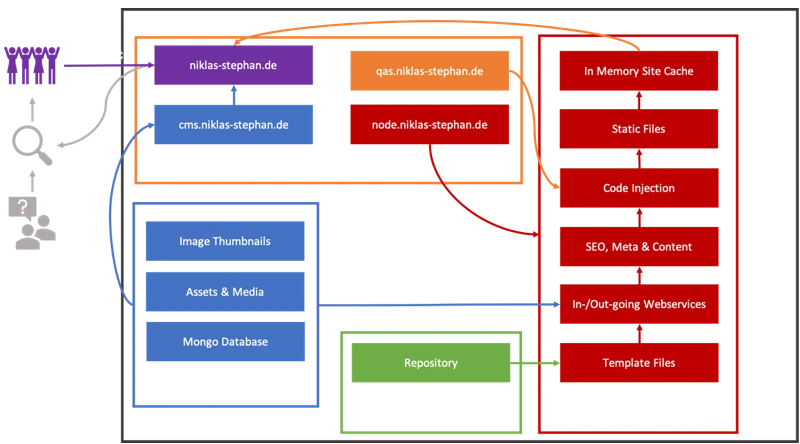
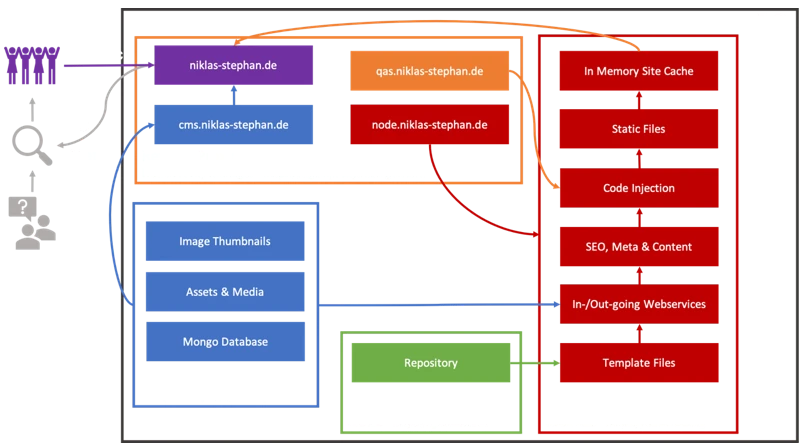
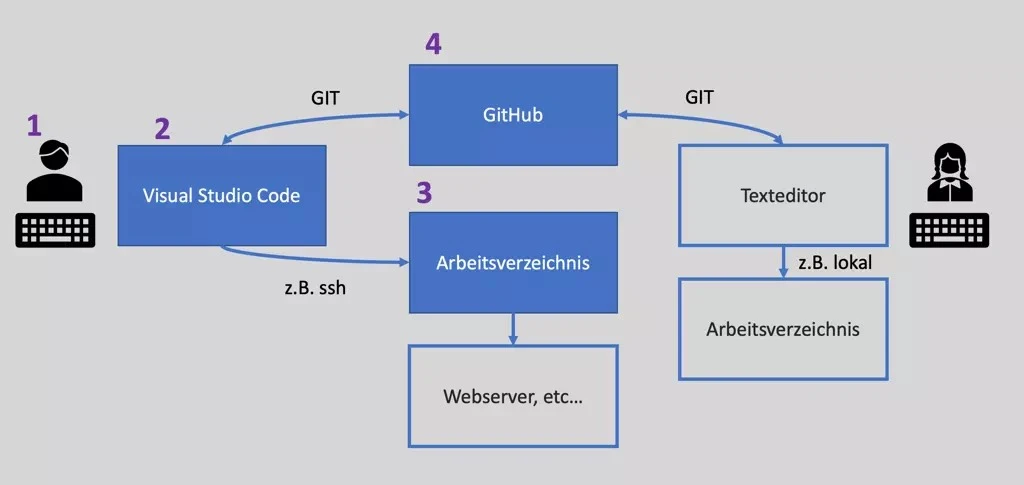
Die Nutzung eines sogenannten Reverse Proxies für die eigene (Docker) Container Landschaft soll zum einen Flexibilität als zum anderen auch erhöhte Sicherheit bieten. Das (virtuelle) Netzwerk der Container wird in verschiedene Zonen aufgeteilt, so dass z.B. Datenbankinstanzen nicht direkt aus dem Internet erreichbar sind. Auch können so z.B. mehrere WordPress Installationen parallel betrieben werden, ohne dass sie sich irgendwie in die „Quere“ kommen. Beides wird in folgender Darstellung illustriert:
Außerdem soll der Zugriff auf die selbst gehosteten Webseiten auschließlich über das verschlüsselte HTTPS Protokoll funktionieren. Die dafür benötigten Zertifikate verwaltet und aktualisiert eine moderne Rerverse Proxy Lösung für uns voll automatisch.
Wie installiere und betreibe ich Caddy als Reverse Proxy?
Zunächst richten wir und ein dediziertes Netzwerk für Caddy und die Container die öffentlich erreichbar sein sollen unter einem gewünschten Namen (hier „Caddy“) mit folgendem Befehl ein:
docker network create caddy
Caddy selbst stellen wir ebenfalls über einen Docker Container zur Verfügung auf dem wir die Ports 80 und 443 exponieren. Eine mögliche Docker Compose Datei „docker-compose.yml“ dazu kann so aussehen:
Bevor wir den Container starten, legen wir im gleichen Verzeichnis eine Datei „Caddyfile“ an. Diese müsst ihr auf eure Bedürfnisse anpassen und orientiert sich hier am oben gezeigten Beispiel:
Nun können wir den Container mit folgendem Befehl starten:
docker compose up -d
Falls irgendetwas nicht funktioniert hilft eine Überprüfung der Logdatei mit:
docker compose logs
Bei Problemen hilft auch ein Blick in die Caddy Community, die viele Problembehandlungen und Konfigurationsbeispiele bereitstellt: https://caddy.community/.
Falls ihr Änderungen/Ergänzungen an dem Caddyfile vornehmt müsst ihr nicht jedes Mal den kompletten Container durchstarten und könnt so Dowtimes durch folgenden Befehl, der die Konfiguration live neu läd, aktualisieren:
Nun gilt es nur noch unsere Applikationen im Caddy Netzwerk sichtbar zu machen. Hier ein Beispiel einer WordPress Installation in der der Applikationsserver von Caddy aus erreicht werden kann, aber nicht der Datenbankserver.
Bis jetzt ist Caddy genau der Kompromiss nach dem ich suchte. Die Konfiguration über eine einzelne Datei lässt sich super einfach sichern und bei Bedarf wiederherstellen. Bei Wunsch nach mehr, stellt Caddy alternativ auch die Konfiguration über eine API als Option bereit. Ein Blick in die technische Dokumentation unter https://caddyserver.com/docs/ offenbart, dass Caddy auch noch viel mehr kann als das gezeigte. Noch nicht herausgefunden habe ich, ob ich ähnlich wie bei Traefik auch zusätzliche Module/Plugins wie Crowdsec, für eine erweiterte Sicherheit aktivieren kann. Generell würde ich nie wieder zurück zum Nginx Proxy Manager wechseln, halte aber Traefik bei komplizierteren Szenarien, evtl. für die bessere Wahl. Für den Hobby Fullstack Entwickler wie mich, ist Caddy aber erstmal eine beinah rundum glücklich Lösung.
WordPress ist nicht gerade berühmt dafür, besonders schnell zu sein. Es bemühen sich daraus reultierend unzählige Plugins auf dem WordPress Marktplatz, mit dem versprechen daran etwas zu ändern, darum die Gunst des Administrators zu gewinnen. Oft, vielleicht sogar meistens, können diese Plugins ihr versprechen nicht halten oder reißen sogar neue Sicherheitslücken im System auf. Vom nichts tun wird die Leistung aber auch nicht besser, weshalb dieser Artikel beschreibt wie man die Performance durch einen Seitencache und einen Objektcache steigern kann, ohne die Sicherheit des Systems aufs Spiel zu setzen.
Wofür sind die Caches da?
Ein Seitencache sagt dem Client (Browser) des Besuchers einer Seite, dass er beim erneuten Besuch oder mehrmaligen Aufruf gleicher Dateien, diese nicht jedes Mal wieder neu vom Server laden zu braucht, sondern die Versionen im seinem lokalen Cache (Speicher) nutzen kann. Dadurch wird die Ladezeit der Seite nicht nur stark beschleunigt, sondern auch der Server auf dem die Website liegt entlastet. Der Seitencache sollte andereseits aber auch nur eine bestimmte Zeit lokal vorgehalten werden, damit Änderungen an der Seite selbst bzw. deren Inhalten auch beim Besucher ankommen. Dies lässt sich über eine direktive in allen gängigen Webserver Systemen einstellen.
Der Objektcahce wiederum agiert auf dem Server selbst und läd häufig benutzte Elemente einer Website in seinen Arbeitsspeicher. In modernen Varianten passiert das über eine sogenannte In-Memory Datenbank, also einer Datenbank die eben ihre Inhalte im Arbeitspeicher ablegt. Das hat neben der gesteigerten Performance den positiven Nebeneffekt, dass weniger von der Festplatte/SSD geladen werden muss und die Hardware so geschont wird.
Seiten Cache in Caddy Reverse Proxy aktivieren
Um den Seiten Cache für unsere WordPress Installationen zu aktivieren fügen wir oben unter den globalen Definitionen in unserem Caddyfile folgende Regel hinzu:
Das war es schon. Nun müssen wir die Caddy Konfiguration nach dem speichern nur einmal neu laden, schon ist der Seitencache überall aktiviert.
Redis Objektcache für WordPress konfigurieren
Um einen Redis Objektcache für WordPress zu aktivieren gibt es mehrere Möglichkeiten. Ich habe mich dafür entschieden einen eigenen Redis Docker Container zu starten der dann von WordPress über ein kleines Plugin angesprochen wird. Dazu müssen wir drei Dinge tun.
docker-compose.yml anpassen
Zunächst ergänezen wir unsere Compose Datei im einen weiteren Block für den Redis Service. Das kann ungefähr so aussehen:
herunterzufahren und nach dem speichern wieder mit
docker compose up -d
zu starten. Nun steht uns der Redis Server zur Verfügung und es geht mit dem nächsten Schritt weiter.
wp-config.php editieren
In der WordPress Konfigurationsdatei „wp-config.php“ müssen wir noch zwei Zeilen ergänzen. Diese Datei liegt im Stammordner euerer WordPress Installation und ist (soll) in der Regel sowohl lese- als auch schreibgeschützt sein. D.h. zum editieren müsst ihr kurz die Berechtigungen auf die Datei so ändern, dass ihr sie beschreiben könnt. Anschließend nicht vergessen die Berechtigung wieder auf den Ausgangswert einzustellen.
Das funktionierte bei mir nur ordnungsgemäß, wenn ich diese Zeilen relativ weit oben in der Datei eingefügt habe.
Plugin installieren
Abschließend kommen wir um die Installation eines kleinen Plugins, dass WordPress sagt den Redis Cache zu nutzen, nicht ganz herum. Installiert auch dafür aus dem Marktplatz das Plugin „Redis Object Cache“ und aktivert dieses.
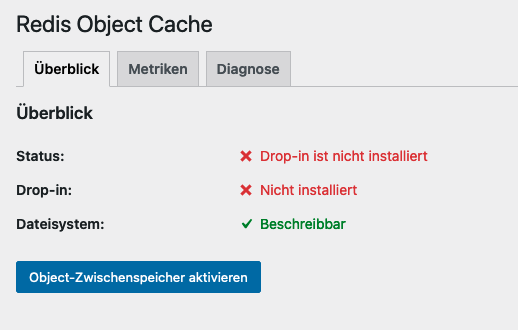
In der Konfiguration des Plugins (unter Einstellungen -> Redis) klickt ihr nun auf „Object-Zwischenspeicher aktivieren“.
Fazit
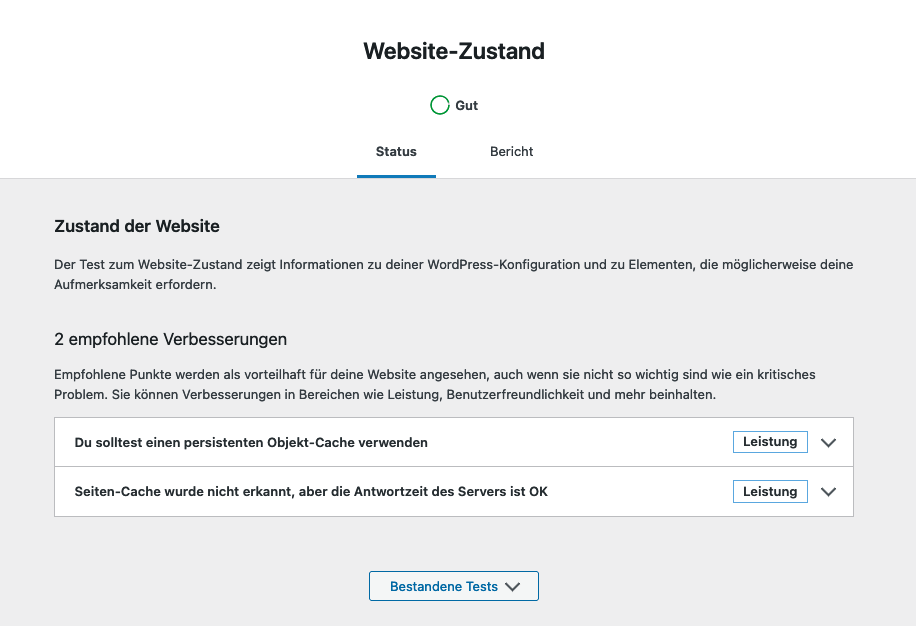
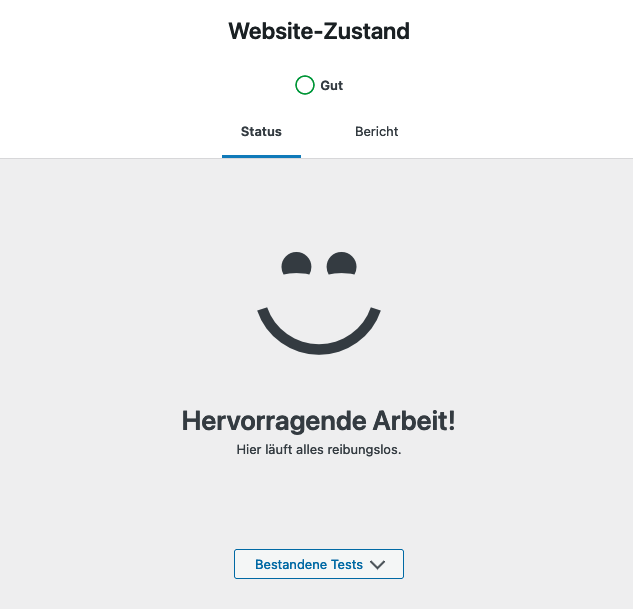
Wenn bis hierhin alles funktioniert hat, seid ihr auch schon fertig und sowohl Seiten- als auch Object-Cache sind aktiv. Das könnt ihr euch auch beim betrachten des Website Zuststands in WordPress bestätigen lassen.
Warum um Himmels willen sollte man Containern feste IP-Adresse zuweisen? Eine absolut berechtigte Frage auf die die Antwort lautet: Am besten nie. Denn: Docker kommt mit einer Art eingebauten DNS- und DHCP-Server und verwaltet die IP-Adresse wunderbar selbst. Leider gibt es trotzdem Spezialfälle in denen man sich das Leben vereinfachen kann, wenn man IPs händisch setzt. So ein Spezialfall wäre z.B. gegeben, wenn die Applikation die in einem Container betrieben wird nicht mit Hostnamen sondern nur mit IP-Adressen umgehen kann, um auf einen weiteren Container zuzugreifen.
Früher war das ein relativ kompliziertes unterfangen, mit den aktuellen Docker (Compose) Versionen ist aber auch das kinderleicht.
IP-Adressen laufender Containers herausfinden
Falls du bereits diverse Container innerhalb eines Netzes am laufen hast, wäre es gefährlich nur einigen davon eine feste IP-Adresse zuzuordnen. Warum? Weil, es dir dann z.B. nach einem Reboot deines Servers passieren könnte, dass sich die automatisch zugewiesene IP eines Containers mit einer von dir fest zugeordneten eines anderen Containers überschneidet. Das Resultat wäre, dass der zweite Container nicht starten kann, da die IP ja bereits vergeben ist.
Um zu erfahren welche IP-Adresse einem Container aktuell zugewiesen ist, hilft uns das Kommando
In unserem Beispiel wollen wir allen Containern die in einem für unseren Caddy Reverse Proxy erstellen Netz liegen feste IP-Adressen vergeben. Falls ihr noch kein solches Netz habt, könnt ihr dieses über den Befehl
anlegen. Nachdem dies erfolgt ist, können wir nun in den Docker Compose Definitionen der einzelnen Container die IP-Adressen 172.20.0.X verwenden. Wobei X für die Zahlen 1-255 steht.
IP-Zuweisung mit Docker Compose
Beginnen wir mit der Zuweisung einer festen IP für unseren Caddy Reverse Proxy:
Nach dem speichern und anschließendem Neustart der Umgebung, ist die IP fest zugeordnet. Entscheidend sind die Blöcke:
networks:
proxy:
ipv4_address: 172.28.0.1
sowie
networks:
proxy:
external: true
Nun verfahren wir genauso mit allen anderen Containern mit einer jeweils individuellen IP und haben unser vorhaben erfolgreich beendet.
Fazit
Auch wenn die Zuweisung fester IP-Adressen relativ einfach ist, erscheint das Ganze als etwas „unsauber“. So widerspricht die Vorgehensweise doch dem Prinzip, dass ich die Definition eines Docker Containers nehmen und jederzeit auf einem anderen Server/Host start kann. Das ist so nun nicht mehr möglich, weil zunächst manuell ein neues Netz angelegt werden muss. Anderseits ist die manuelle Erstellung des Netzes sowieso erforderlich, wenn man eine Art DMZ (eigenes Netz) für seinen Reverse Proxy definiert. Nur der manuell vergebene Subnetzbereich ist hier der zusätzliche Aufwand. So bleibt die Verwendung fester IP-Adressen als ein Spezialfall der nur in bestimmten Szenarien Sinn macht.
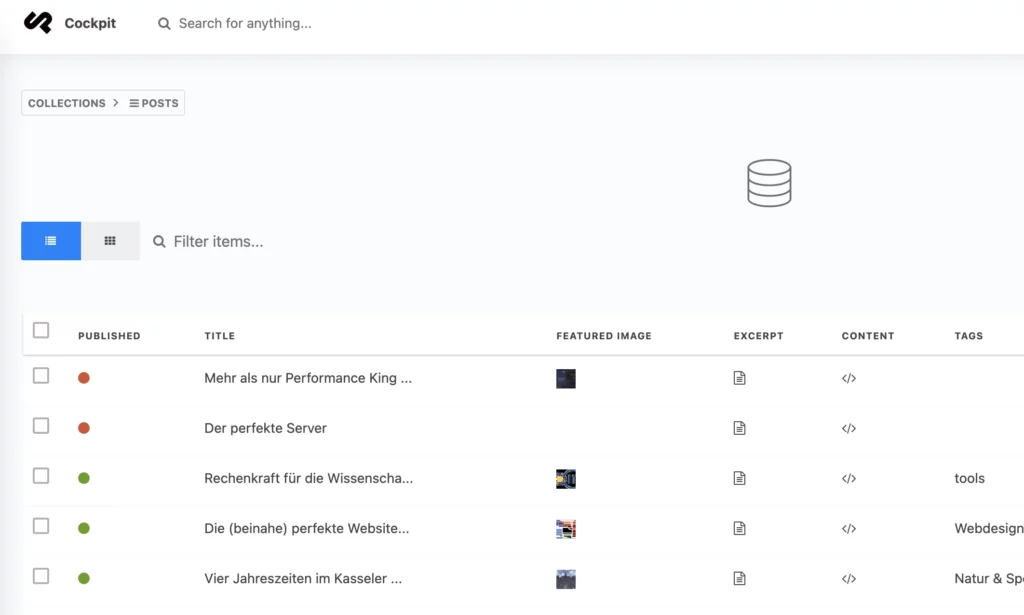
Warum sollte man sein eigenes Web Content Management System (WCMS) erstellen wollen, es gibt doch schon hunderte?! Völlig korrekt und es gibt auch keinen wirklichen Grund so etwas zeitintensives zu tun, außer natürlich man ist mit dem was es gibt nicht so richtig zufrieden und/oder möchte einfach selber wissen und ausprobieren wie man so etwas angehen kann. Genau mit dieser Motivation, und der ursprünglichen Intention für meine persönliche Website ein neues Layout zu entwickeln, habe ich mir innerhalb eines Monats ein eigenes WCMS erstellt: nCMS – “niklas stephan’s Content Management System” oder auch “node-red Content Management System” oder “not another Content Management System”!
Was ist nCMS und was kann es?
nCMS ist ein Flat-File und Headless Web Content Management System. D.h. im Gegensatz zu z.B. zu WordPress, kommt es ohne eine Datenbank aus und besteht aus Dateien. NCMS basiert im Backend auf Node-Red und darin entwickelten Node.js JavaScript Funktionen. Änderungen am Code von NCMS werden durch Deployments in Node-Red geschrieben und die Änderungen an Dateien über GIT in Github synchronisiert und versioniert. Änderungen an Inhalten wie neue Posts werden ebenfalls über Deployments, manuell oder als Webhook gestartet. Alle Dateien werden darauf hin generiert und einem Webserver als statische Dateien zur Verfügung gestellt. Das heisst dass der Abruf der Inhate über eine mit nCMS erstellte Website rasend schnell ist. Das erstellen einzelner Blog Beiträge erfolgt in Markup Syntax in einem beliebigem Texteditor.
Weitere bis jetzt integrierte Features sind:
Multi-Language Support für Blog Beiträge und alle Seiten
Kommentarfunktion in den Blogbeiträgen
Media Management über einfachen Datei-Upload
Template- und Snippet-basierte Erstellung des HTML Gerüsts
Explizit kein Einsatz von Frontend Frameworks wie Vue oder Angular, sondern reines “Vanilla” Javascript.
Automatische Generierung von Meta-Daten für Social Media Integration und SEO
Volltextsuche auf Basis eines automatisch generierten lokalen Index
Freigabefunktion von Posts über ein “published” Attribut
Schneller, aufgeräumter und einfacher als WordPress und andere?
Ja, ja, ja. Wie genau, erläutere ich hier.
Schnell
Backend – Ein Deployment (erzeugen der statischen Files für den Webserver) dauert zwischen 70 und 320 Millisekunden.
Frontend – z.B. die Startseite ist trotz aller Animationen, Effekte und Bilder nur 670KB groß und kann in zwischen 100 und 300 Millisekunden vom Client vollständig geladen werden.
Aufgeräumt
Backend: Der Einsatz von Node-Red gibt eine grafische Übersicht und gewährleistet so, dass wir den Überblick nicht verlieren. Dazu später noch mehr.
Frontend: Durch den Verzicht auf JavaScript Frameworks und der Einfachheit des Systems an sich, werden wir mit sauberen HTML Code bei der Ausspielung belohnt. Für https://niklas-stephan.de habe ich zwar für das Frontend UI auf das HTML5 Grundgerüst von Bootstrap 5 zurück gegriffen, aber das fällt nicht mehr schwer ins Gewicht, und kommt mittlerweile im Standard ebenfalls ohne das aufgeblähte jQuery Framework zurecht.
Einfach
Backend: Assets, Medien, Templates und Snippets werden über Visual Studio Code oder einen anderen Texteditor + Dateimanager bereitgestellt. In Node-Red wird das alles zusammengefügt, durch JavaScript Code und node.js Module um Funktionalitäten erweitert und das Endergebnis schließlich in Form von statischen Dateien in ein Verzeichnis auf einem nginx webserver zur Verfügung gestellt. Das ist der Kern von nCMS.
Frontend: Die Wahl zwischen Deutsch und Englisch erfolgt entweder automatisch oder wird manuell festegelegt. Es gibt eine Startseite, eine Seite zu Suche, eine Seite zu Datenschutz und Impressum, eine Seite zum abfangen ungültiger Aufrufe und eine Seite mit der Übersicht über alle Posts. Selsbstredend ist das komplette UI auf alle Endgerätearten zur Darstellung optimiert.
Hinter den Kulissen
Der komplette Aufbau von nCMS erfolgt in einer Docker-Compose Umgebung. Alle Dateien aus dem Volume src liegen ebenfalls auf https://github.com/handtrixx/ncms.
Erkärungsbedürftig sind hier eigentlich nur die Netzwerkonfiguration und die verschiedenen Volumes. Wie auch in meinen anderen Beiträgen zu Matomo, Boinc und anderen setze ich auf meinem Cloud Server einen Reverse Proxy auf Basis des Nginx Proxy Managers (https://hub.docker.com/r/jc21/nginx-proxy-manager) ein. Das Volume/Verzeichnis ./dist ist in meinem Reverse Proxy ebenfalls über ein ln -s verlinkt, so dass man keine doppelten Deployments machen muss und ein weiterer Webserver obsolet bleibt. Node-Red selbst, also das Backend ist über eine eigene Subdomain erreichbar.
Verzeichnisstruktur
Im Verzeichnis ./src befinden sich folgende Unterordner:
assets
css
fonts
img
js
json
md
posts
media
x
snippets
templates
In das Verzeichnis assets und dessen Unterordner gehören alle im Frontend wiederholt benötigten Dateien, wie z.B. css und javascript von Bootstrap 5 (https://getbootstrap.com/), aber natürlich vor allem auch eigene Stylesheets und Javascript Funktionen. Im Unterordner json legen wir unsere statischen Übersetzungschlüssel ab.
Der Ordner md enthält in seinem Unterordner posts offensichtlich alle unsere in Markup geschriebenen Posts, welche auch an ihrer Dateiendung .md erkennbar sind.
In das Verzechnis media und maximal eine Unterodnerebene tiefer können wir alle Bilder “werfen” die wir in unseren Posts verwenden wollen. Diese werden dann während des Deployments automatisch ins platzsparende .webp Format konvertiert und ein Thumbnail für jedes Bild generiert.
Im Ordner snippteshaben wir alle HTML Elemente die wir auf allen Seiten immer wieder benötigen gelegt.
Analog dazu liegen im Verzeichnis templates die Ausgangsdateien unseres Frontends, die während des Deployments mit Inhalt angereichtert werden.
Im Verzeichnis Templates befinden sich folgende Dateien: 404.html – Die Fehlerseite die immer dann angezeigt wird, wenn eine ungültige Abfrage auf die Website erfolgt. blog.html – Die Seite die die Übersicht über alle Posts bereit stellt. index.html – Die Startseite mit ihren Inhalten. post.html – Die Vorlage aus der die einzelen Beitragsseiten gerendert werden. privacy-policy.html – Die Seite zu Datenschutz und im Impressum auf die im Footer verllinkt ist und die somit von überall aus erreichbar ist und sein muss. robots.txt – Infos für die Crawler von Suchmaschinen. search.html – Meine Seite auf der man Suchen kann und die über einen json Index sämtliche Suchergebnisse ohne Abfrage am Server bereitstellt.
Snippets
Die Snippets die später im Deployment in alle HTML Templates eingeschläust werden sind footer.html, head.html, navbar.html, script.html . Durch die Aufteilung in diese Snippets haben wir den massiven Vorteil, dass wir im Falle einer gewünschten Anpassung z.B. im Navigationsmenü, diese nur genau einmal durchführen müssen um sie auf allen Seiten zu ändern.
Programmlogik mit node.js und Node-Red
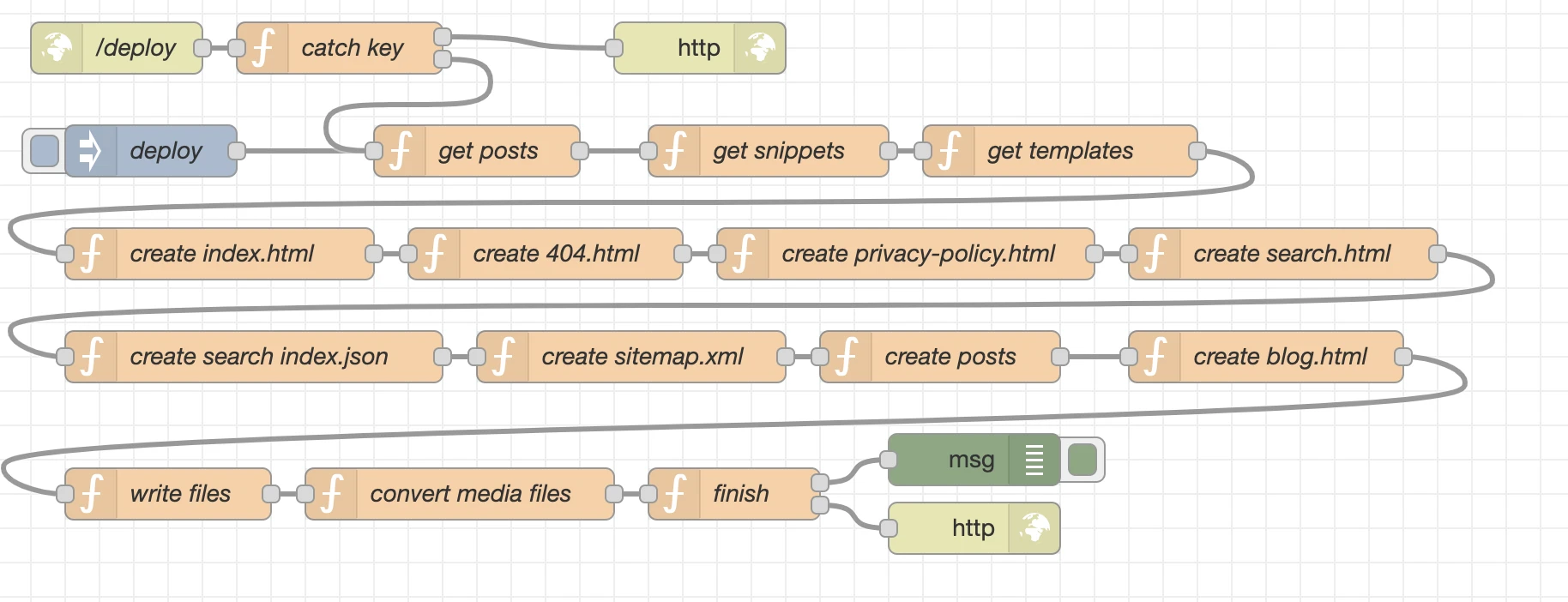
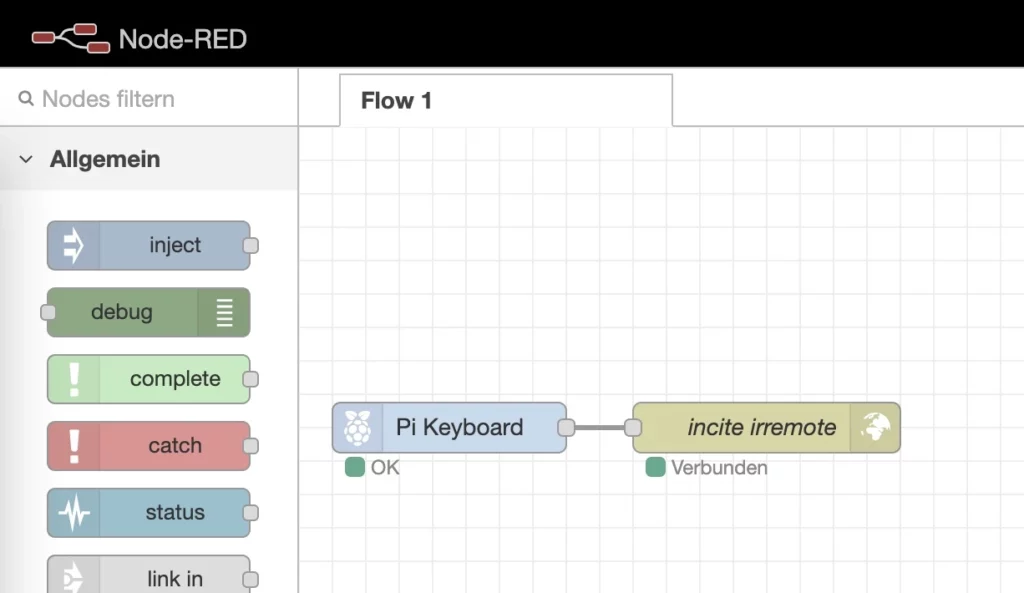
Node-Red basiert auf node.js und erlaubt uns in einer Art Ablaufdiagramm verschiedene Elemente und Funktionen miteinander zu verbinden. Das nennt sich in Node-Red “Flow”. In NCMS nutze ich auch nur diese Basisfunktionalität von Node-Red und keine weitere Plug-Ins aus der Palette. Stattdessen lade ich in den verschiedenen Nodes node.js Pakete nach um den Funktionsumfang des Systems zu erweitern.
Im folgenden eine Erläuterung zu den einzelen Nodes.
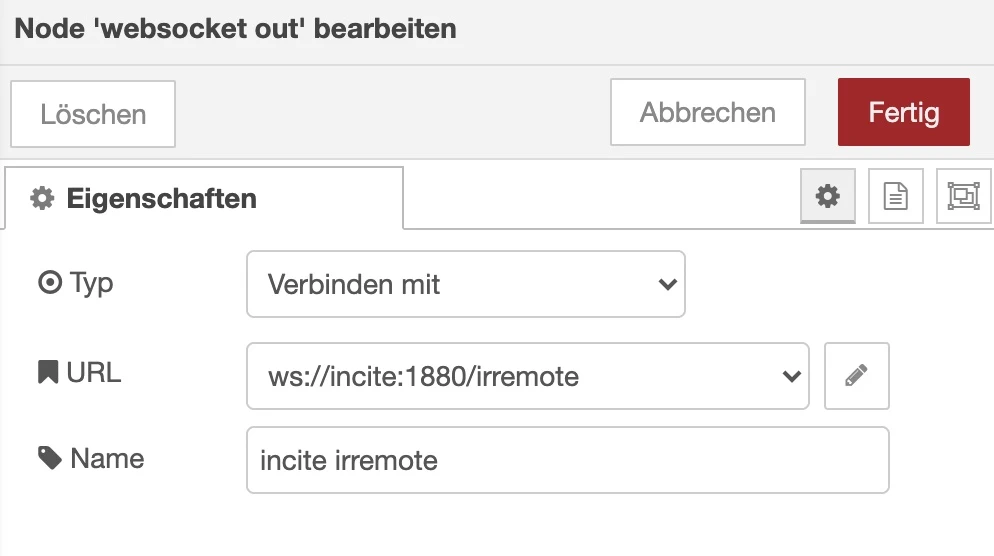
/deploy
Hierbei handelt sich um einen lauschenden http in Node, um den Start eines Deplyoments durch einen Webhook zu starten. D.h. z.B. durch curl -X POST -d 'key=----' https://ncms.niklas-stephan.de/deploy startet man das Deployment.
catch key
Natürlich soll nicht einfach jeder ein Deployment starten können, deshalb noch eine kleine Sicherheitsabfrage im catch key Node. Im Node unter “Setup” wird das npm Modul fs-extra geladen und als fse bereit gestellt, damit wir Zugriff auf das Dateisystem haben und den im Ordner /data hinterlegten key mit dem vergleichen können, der uns für das Deployment im Webhook zur Verfügung gestellt wurde. Die Funktion selbst sieht dann so aus:
Auch hat dieser Node 2 Ausgänge. Falls die beiden keys übereinstimmen wird mit dem Deployment fortgefahren – Ausgang 2. Falls aber nicht, dann wird eine Fehlernachricht an Ausgang 1 übergeben und das Deployment damit abgebrochen.
deploy
Startet das Deployment ebenfalls, aber eben manuell über die Node-Red Oberfläche und nicht als Webhook.
get posts
In diesem Node laden wir den Inhalt aller Posts aus den *.md Dateien und speichern diesen als Objekte in einem Array zu späteren Verwendung ab. Außerdem machen wir neben dem fs-extra Modul noch intensiven Gebrauch des Moduls markdown-it und Plugins für diesen. markdown-it (https://github.com/markdown-it/markdown-it) hilft uns dabei den Inhalt von Markup nach HTML zu konvertieren.
msg.baseurl = "https://niklas-stephan.de"
msg.dist = {};
msg.posts = [];
const path = '/src/md/posts/';
const postfiles = fse.readdirSync(path)
const alength = postfiles.length;
for (var i=0; i<alength; i++) {
var srcFile = path+postfiles[i];
var distFilename = postfiles[i].split('.')[0]+".html";
var srcContent = fse.readFileSync(srcFile, 'utf8')
var md = new markdownIt({
html: true,linkify: true,typographer: true,breaks: true})
.use(markdownItFrontMatter, function(metainfo) {meta = JSON.parse(metainfo);})
.use(markdownItLinkifyImages, {target: '_blank',linkClass: 'custom-link-class',imgClass: 'custom-img-class'})
.use(markdownItLinkAttributes, { attrs: {target: "_blank",rel: "noopener",}
});
distContent = md.render(srcContent);
let data = {"srcFile":""+srcFile+"","srcContent":""+srcContent+"","distContent":""+distContent+"","distFilename":""+distFilename+"",...meta};
msg.posts.push(data)
}
return msg;
get snippets
Über das npm Modul fs-extra laden wir den Inhalt unserer snippets und speichern diese als Array msg.snippets, damit wir später im Flow darauf zugreifen können.
Nun fangen wir an die Inhalte der einzelnen Dateien zu generieren, den Start macht unsere index.html Datei. Die obere Hälfte des Codes betrifft das generieren der Meta Tags für Social Media und Suchmaschinen. Im zweiten Block fügen wir in die Platzhalter des Templates die Werte Snippets, den Seitentitel, sowie die Metadaten ein. Letztlich steht unsere fertige index.html als Objekt msg.dist.index in unserem Flow bereit um später als Datei geschrieben zu werden.
msg.dist.index = "";
var ogmetalang = "de_DE";
var ogmeta = `
<meta property="og:type" content="website">
<meta property="og:locale" content="`+ogmetalang+`">
<meta property="og:site_name" content="niklas-stephan.de">
<link rel="canonical" href="`+msg.baseurl+`/index.html">
<meta name="description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta property="og:title" content="Projects & Blog - niklas-stephan.de">
<meta property="og:description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta property="og:url" content="`+msg.baseurl+`/index.html">
<meta property="og:image" content="`+msg.baseurl+`/assets/img/me_logo.webp">
<meta property="og:image:secure_url" content="`+msg.baseurl+`/assets/img/me_logo.webp">
<meta name="twitter:card" content="summary">
<meta name="twitter:description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta name="twitter:title" content="Projects & Blog - niklas-stephan.de">
<meta name="twitter:image" content="`+msg.baseurl+`/assets/img/me_logo.webp">`
msg.dist.index = msg.templates["index.html"].replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
msg.dist.index = msg.dist.index.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
msg.dist.index = msg.dist.index.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
msg.dist.index = msg.dist.index.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
msg.dist.index = msg.dist.index.replace("<!-- PAGE TITLE -->","Home");
msg.dist.index = msg.dist.index.replace("<!-- meta tags -->",ogmeta);
return msg;
create 404.html
msg.dist.errorpage = "";
msg.dist.errorpage = msg.templates["404.html"].replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
msg.dist.errorpage = msg.dist.errorpage.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
msg.dist.errorpage = msg.dist.errorpage.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
msg.dist.errorpage = msg.dist.errorpage.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
msg.dist.errorpage = msg.dist.errorpage.replace("<!-- PAGE TITLE -->","Page not found");
return msg;
Die 404.htmlist schnell zusammen gebaut. wir fügen alle Snippets in unser Template ein und geben der Seite einen Namen. Abschließend steht unser Objekt als msg.dist.errorpage zur Verfügung.
create privacy-policy.html
Genauso ein “Low-Brainer” ist die Seite mit Datenschutz und Impressum und schnell als msg.dist.privacy aufbereitet.
msg.dist.privacy = "";
msg.dist.privacy = msg.templates["privacy-policy.html"].replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
msg.dist.privacy = msg.dist.privacy.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
msg.dist.privacy = msg.dist.privacy.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
msg.dist.privacy = msg.dist.privacy.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
msg.dist.privacy = msg.dist.privacy.replace("<!-- PAGE TITLE -->","Datenschutz & Impressum");
return msg;
create search.html
Bevor es wieder ein wenig komplizierter wird, zunächst noch die einfach Erzeugung des Objekts msg.dist.searchindex zur späteren Verwendung.
msg.dist.search = "";
msg.dist.search = msg.templates["search.html"].replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
msg.dist.search = msg.dist.search.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
msg.dist.search = msg.dist.search.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
msg.dist.search = msg.dist.search.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
msg.dist.search = msg.dist.search.replace("<!-- PAGE TITLE -->","Suche");
return msg;
create search index.json
Um den Suchindex aufzubauen, der später eine Suche ermöglicht ohne eine Abfrage an den Server zu stellen, verwenden ich eine for Schleife die durch alle Elemente im Array msg.posts läuft und für jeden Beitrag einen Eintrag im Index als JSON Objekt erzeugt. Letztlich wird der Index als Objekt msg.dist.searchindex bereit gestellt.
var alength = msg.posts.length;
var index = "[";
for (var i=0; i<alength; i++) {
index = index+`{"lang":"`+msg.posts[i].language+`","link":"/posts/`+msg.posts[i].distFilename+`","headline":"`+msg.posts[i].title+`","content":"`+msg.posts[i].distContent.replace(/[^a-zA-Z0-9]/g, ' ')+`"},`;
}
index = index.slice(0, -1);
index = index+"]";
msg.dist.searchindex = index;
return msg;
create sitemap.xml
Bei der Erzeugung der Sitemap gehen wir ähnlich vor wie beim Suchindex. Anstelle einer klassischen for Schleife verwende ich die Javascript forEach() Funktion, die im Endeffekt das gleiche bewirkt, nur etwas moderner ist.
var xml = `<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.sitemaps.org/schemas/sitemap/0.9 http://www.sitemaps.org/schemas/sitemap/0.9/sitemap.xsd">
<url>
<loc>`+msg.baseurl+`/</loc>
<priority>1.00</priority>
</url>
<url>
<loc>`+msg.baseurl+`/index.html</loc>
<priority>0.80</priority>
</url>
<url>
<loc>`+msg.baseurl+`/blog.html</loc>
<priority>0.80</priority>
</url>`
msg.posts.forEach(postxml);
xml = xml + `
</urlset>`
msg.dist.sitemap = xml;
return msg;
function postxml(item) {
if (item.published == true ) {
xml = xml + `
<url>
<loc>`+msg.baseurl+`/posts/`+item.distFilename+`.html</loc>
<priority>0.64</priority>
</url>`
}
}
create posts
Wir haben zur im get posts Node bereits den Inhalt der einzelnen Posts im Array msg.posts konvertiert und bereit gestellt. Jetzt wollen wir dies noch dahingehend finalisieren, dass wir analog zu den zuvor erzeugten Dateien auch für jeden Post eine einzelne Datei erzeugen können und lege diese wiederum als Objekt im Objekt msg.dist.posts ab.
msg.dist.posts = {};
var alength = msg.posts.length;
var data = "";
var ogmetalang = "";
var ogmeta = "";
var postdate = "";
for (var i=0; i<alength; i++) {
if (msg.posts[i].language == "de") {
ogmetalang = "de_DE"
} else {
ogmetalang = "en_US"
}
img = msg.posts[i].imgurl.split('.')[0]+".webp";
ogmeta = `
<meta property="og:type" content="website">
<meta property="og:locale" content="`+ogmetalang+`">
<meta property="og:site_name" content="niklas-stephan.de">
<link rel="canonical" href="`+msg.baseurl+`/posts/`+msg.posts[i].language+`/`+msg.posts[i].distFilename+`">
<meta name="description" content="`+msg.posts[i].excerpt+`">
<meta property="og:title" content="`+msg.posts[i].title+`">
<meta property="og:description" content="`+msg.posts[i].excerpt+`">
<meta property="og:url" content="`+msg.baseurl+`/posts/`+msg.posts[i].language+`/`+msg.posts[i].distFilename+`">
<meta property="og:image" content="`+msg.baseurl+`/media/full/`+img+`">
<meta property="og:image:secure_url" content="`+msg.baseurl+`/media/full/`+img+`">
<meta name="twitter:card" content="summary">
<meta name="twitter:description" content="`+msg.posts[i].excerpt+`">
<meta name="twitter:title" content="`+msg.posts[i].title+`">
<meta name="twitter:image" content="`+msg.baseurl+`/media/full/`+img+`">`
postdate = '<small class="c-gray pb-3" id="postdate">'+msg.posts[i].date+'</small>';
data = "";
data = msg.templates["post.html"];
data = data.replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
data = data.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
data = data.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
data = data.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
data = data.replace("<!-- mardown content from posts -->",msg.posts[i].distContent);
data = data.replace("<!-- Post Headline -->", msg.posts[i].title);
data = data.replace("<!-- postdate -->", postdate);
data = data.replace("<!-- Post Image -->", '<img src="/media/thumb/'+img+'" class="img-fluid mb-2" alt="postImage">');
data = data.replace("<!-- PAGE TITLE -->",msg.posts[i].title);
data = data.replace("<!-- meta tags -->",ogmeta);
msg.dist.posts[msg.posts[i].distFilename] = data;
}
return msg;
create blog.html
Nun unser letzter vorbereitender Streich, die Erzeungung der Übersicht aller Posts im Objekt msg.dist.blog. Es ist am Umfang der Funktion ersichtlich, dass hier etwas mehr als bei den anderen Dateien passiert. Zuerst sammeln wir alle definierten Kategorien aus den einzelnen Posts über eine for Schleife ein um dann doppelt vorhandene Werte wieder aus dem erzeugtem Array zu löschen. Das brauchen wir damit die Besucher unserer Website später über Kategorien filtern können. Jede Kategorie bekommt außerdem eine eindeutige Farbe, die einer CSS Klasse in unserem Stylesheet entspricht, zugeordnet. Als nächstes extrahieren wir aus den Metadaten der Posts noch Titel, Kurzbeschreibung, Datum und Bild. Während dieser for-Schleife verhindert eine if-Bedingung, dass wir unveröffentliche Posts zur Auswahl aufbereiten. Abschließend erzeugen wir aus den ermittelten Werten den entsprechenden HTML Code, fügen die Daten der Snippets ein, ergänzen die Meta Informationen zur Seite und schreiben das Ganze in das Objekt msg.dist.blog.
//get categories from all posts and extract unique ones
var categories = [];
for (var i=0 ; i<msg.posts.length;i++) {
if (msg.posts[i].published == true) {
for (var j = 0; j < msg.posts[i].keywords.length; j++) {
categories.push(msg.posts[i].keywords[j]);
}
}
}
var uniqueCategories = [...new Set(categories)];
// define a color to stick for each category
const colorcat = {};
var catcolors = ["green", "red", "blue", "orange", "yellow", "pink", "purple","indigo"];
var c=0;
for (const key of uniqueCategories) {
colorcat[key] = catcolors[c];
c = c+1;
}
//generate and set html for categorie selection
var cathtml = "";
for (var k = 0; k < uniqueCategories.length; k++) {
cathtml = cathtml + `<button data-filter=".cat-`+uniqueCategories[k]+`" type="button"
onclick="sort()" class="btn bg-` + catcolors[k] + ` c-white me-2">` + uniqueCategories[k]+`</button>`;
}
msg.dist.blog = msg.templates["blog.html"].replace("<!-- CATEGORIES -->", cathtml);
// get card content from all posts and generate html
var posthtml = "";
for (var l = 0; l < msg.posts.length; l++) {
if (msg.posts[l].published == true) {
var link = msg.posts[l].filename.slice(0, -3)+".html";
//get color for current post
var postcolor = "";
for (const key in colorcat) {
if (key == msg.posts[l].keywords[0]) {
postcolor = colorcat[key];
}
}
imgurl = msg.posts[l].imgurl.split('.')[0]+".webp";
posthtml = posthtml + `
<div class="col-sm-6 col-lg-4 my-4 filterDiv cat-`+msg.posts[l].keywords[0]+` lang-`+ msg.posts[l].language + `">
<span class="date hidden d-none">`+ msg.posts[l].date + `</span>
<span class="name hidden d-none">`+ msg.posts[l].title + `</span>
<div onclick="goto('`+ link+ `','blog')" class="card h-100 d-flex align-items-center bo-`+postcolor+`">
<div class="card-header bg-`+ postcolor + `">` + msg.posts[l].keywords[0] + `</div>
<div class="card-img-wrapper d-flex align-items-center">
<img src="media/thumb/`+ imgurl + `"
class="card-img-top" alt="iot">
</div>
<div class="card-body">
<h5 class="card-title">`+ msg.posts[l].title + `</h5>
<p class="card-text">
`+ msg.posts[l].excerpt + `
</p>
</div>
<div class="card-footer small text-center c-gray pdate">
`+msg.posts[l].date+`
</div>
</div>
</div>
`;
}
}
msg.dist.blog = msg.dist.blog.replace("<!-- POSTS -->", posthtml);
var ogmetalang = "de_DE";
var ogmeta = `
<meta property="og:type" content="website">
<meta property="og:locale" content="`+ogmetalang+`">
<meta property="og:site_name" content="niklas-stephan.de">
<link rel="canonical" href="`+msg.baseurl+`/blog.html">
<meta name="description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta property="og:title" content="Projects & Blog - niklas-stephan.de">
<meta property="og:description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta property="og:url" content="`+msg.baseurl+`/blog.html">
<meta property="og:image" content="`+msg.baseurl+`/assets/img/me_logo.webp">
<meta property="og:image:secure_url" content="`+msg.baseurl+`/assets/img/me_logo.webp">
<meta name="twitter:card" content="summary">
<meta name="twitter:description" content="Projekte und Posts aus der Welt von IoT, Musik und mehr">
<meta name="twitter:title" content="Projects & Blog - niklas-stephan.de">
<meta name="twitter:image" content="`+msg.baseurl+`/assets/img/me_logo.webp">`
msg.dist.blog = msg.dist.blog.replace("<!-- meta tags -->",ogmeta);
msg.dist.blog = msg.dist.blog.replace("<!-- html head from head.html snipppet -->",msg.snippets["head.html"]);
msg.dist.blog = msg.dist.blog.replace("<!-- Top Navigation from navbar.html snipppet -->",msg.snippets["navbar.html"]);
msg.dist.blog = msg.dist.blog.replace("<!-- footer navigation from footer.html snipppet -->",msg.snippets["footer.html"]);
msg.dist.blog = msg.dist.blog.replace("<!-- Javascript from script.html snipppet -->",msg.snippets["script.html"]);
msg.dist.blog = msg.dist.blog.replace("<!-- PAGE TITLE -->","Projekte & Blog");
return msg;
write files
Jetzt wollen wir endlich unsere mühevoll erzeugten Objekte in msg.dist als reale Dateien festschreiben. In unserer Funktion “write files” binden wir dafür wieder das npm modul fs-extra als fse ein. Alle erzeugten Dateien sollem im Verzeichnis /dist/ landen. Gleichzeitig wollen wir auch alle spuren vorheriger Deployments löschen, damit uns “Dateileichen” und ähnliche nicht zu Inkonsitenzen führen. Das den fse Funktionen vorangestellte await stellt eine sequentielle Ausführung der einzelnen Schritte sicher, in dem es wartet bis der jeweilige Aufruf auch komplett abgeschlossen ist. Also wird in der Funktion im ersten Schritt das Verzeichnes /dist komplett geleert und dann alle benötigten Unterordner wieder leer erstellt. Als nächstes kopieren wir unsere Assets von /src/assets/ nach /dist/assets/ und machen das Gleiche mit der robots.txt Datei. Anschließend schreiben wir die Inhalte der Objekte in msg.dist in die jeweilige Datei fest, um dann in einer Schleife durch alle Posts zu gehen und diese ebenfalls in das Dateisystem zu schreiben.
Noch etwas komplexer ist die Erzeugung der Mediendatein. Die Dateien aus dem Verzeichnis /src/media/und einer Unterordnerebene tiefer, wollen wir ins Speicher sparende .webp Format konvertieren und zusätzlichen jeweils einen Thumbnail in geringerer Auflösung generieren. Außerdem wollen wir das nur Medien mit den Quellformaten .jpg, .jpeg, .png oder .gif konvertiert werden. Alle anderen Dateien werden ohne Änderung direkt nach /dist/media/full/ kopiert. Um uns die Arbeit zu erleichten greifen wir auf die npm Module fs-extra als fse und sharp zurück. Man beachte auch, das ich das await Kommando bewusst bei der Erzeugung der Dateien ausspare, so dass die Schleifen bereits mit der nächsten Datei aus ihren Arrays starten, bevor die Schreiboperation abgeschlossen ist. Das beschleunigt das Deployment um einen sehr großen Faktor, bei dem geringen Risiko bzw. dem akzeptieren Umstand, dass eine Mediendatei noch nicht geschrieben/verfügbar ist, wenn das Deplyoment abgeschlossen ist.
var srcpath = '/src/media/';
var fullpath = '/dist/media/full/';
var thumbpath = '/dist/media/thumb/';
const filetypes = ["jpg", "jpeg", "png", "gif", "webp"];
const mediafiles = fse.readdirSync(srcpath);
const alength = mediafiles.length;
var mediafile = "";
var targetfile = "";
for (var i=0; i<alength; i++) {
mediafile = mediafiles[i];
if (mediafile.includes(".")) {
targetfile = mediafile.split('.')[0];
if (filetypes.includes(mediafile.split('.')[1]) ) {
sharp(srcpath+mediafile)
.toFile(fullpath+targetfile+'.webp');
sharp(srcpath+mediafile).resize({ width: 440 })
.toFile(thumbpath+targetfile+'.webp');
} else {
fse.copySync(srcpath+mediafile, fullpath+mediafile)
}
} else {
var subsrcpath = srcpath+mediafile+"/";
var subfullpath = fullpath+mediafile+"/";
var subthumbpath = thumbpath+mediafile+"/";
var submediafiles = fse.readdirSync(subsrcpath);
var blength = submediafiles.length;
await fse.mkdirSync(subfullpath);
await fse.mkdirSync(subthumbpath);
for (var j=0; j<blength; j++) {
submediafile = submediafiles[j];
subtargetfile = submediafile.split('.')[0];
if (filetypes.includes(submediafile.split('.')[1]) ) {
sharp(subsrcpath+submediafile)
.toFile(subfullpath+subtargetfile+'.webp');
sharp(subsrcpath+submediafile).resize({ width: 440 })
.toFile(subthumbpath+subtargetfile+'.webp');
} else {
fse.copySync(subsrcpath+submediafile, subfullpath+submediafile)
}
}
}
}
return msg;
finish
Unser Deployment nähert sich dem Ende. Wir errechnen noch die Dauer des Deployments und setzen einen Zeitstempel um diese Informationen in der Datei /dist/deploy.log festzuhalten. Die Datei wird dann wieder mit dem npm Modul fs-extra als fse geschrieben. Je nach Auslöser des Depyloyments, also manuell vs. webhook, wird dann abschließnd an ein Debug Node oder an den Debug Node und einen http-out Node weitergeleitet.
var endtime = Date.now();
var duration = endtime-msg.starttime;
duration = duration;
let yourDate = new Date()
var depdate = yourDate.toISOString();
var log = "Deployment duration: "+duration+" ms \n";
log = log+"Deployment timestamp: "+depdate;
msg.statusCode = 200;
fse.writeFileSync('/dist/deploy.log', log);
msg.payload = log;
if (msg.type != "manual") {
return [msg,msg];
} else {
return [msg,null];
}
msg & http
Fertig! Die Beiden Nodes msg und http dienen zum sauberen Abschluss unseres Deployments. Der “http out” Node liefert den zuvor definierten Body als Nachricht zurück an den aufrufenden Webhook.
Der “msg” Debug Node zeigt uns den kompletten Inhalt des Deployments im Debugger von Node-Red an, wenn aktiviert.
Zugegeben, hätte ich eine Stoppuhr genutzt um aufzuzeichnen wie lange die Entwicklung von nCMS gedauert hat, vielleicht hätte ich irgendwann abgebrochen. Aber: von Start bis Ende des Projekts, ganz wie bei einem rundenbasierten Strategiespiel, war regelmäßig der “nur diese eine Sache noch” Moment da. Eine Menge Spaß hat es außerdem gemacht, mit Hilfe von Node-Red immer ausgefeiltere JavaScript Funktionen zu entwickeln. Der fest integrierte Debugger war dabei eine fast genauso große Hilfe, wie die Möglichkeit in Node-Red javascript Funktionen maximal einfach auf weitere node.js Module zuzugreifen. Falls ihr mal eine ähnliches Vorhaben umsetzen möchtet, könnt ihr gerne meine Quellen Auf Github forken. Einige verbesserungswürdige Schwachstellen gibt es natürlich auch noch. Zum Beispiel an den Stellen, bei denen ich im Node-Red Backend auf das Frontend referenziere. Das macht das Ganze etwas weniger flexibel, denn wenn wirklich mal jemand meine Quellen nutzen möchte, müsste sie/er sich entsprechend noch in das Frontend einarbeiten. Und überhaupt bin ich hier im Artikel nicht auf das HTML5 Frontend mit javascript Funktionen, CSS und HTML weiter eingegangen. Vielleicht folgt das ein andernmal.
Quellen / Weiterführende Links
Hier nochmal alle Quellen, Links und Dateien aus dem Artikel zusammen aufgeführt:
Wenn man sich zum Einem für wissenschaftliche Projekte begeistern kann und zum Anderen ein wenig Rechenleistung übrig hat, dann sollte man sich das Open Source Projekt und Werkzeug Boinc einmal genauer anschauen. In diesem Artikel berichte ich darüber, was Boinc eigentlich ist und wie man es einfach installieren kann.
Volunteer-Computing / Ehrenamtliches Rechnen?
Volunteer-Computing (zu deutsch: ehrenamtliches / freiwilliges Rechnen) beschreibt eine Technik der Anwendungsprogrammierung bei der einzelne Computernutzer Rechnerkapazitäten wie Rechenzeit und Speicherplatz auf freiwilliger Basis einem bestimmten Projekt zur Verfügung stellen, um unter Anwendung des verteilten Rechnens ein gemeinsames Ergebnis zu berechnen.“
Quelle: Wikipedia
Das heisst, dass jeder der ein wenig Rechenleistung entbehren kann, sich an wissenschaftlichen Projekten beteiligen kann, um diesen dabei zu helfen bestimmte Problemstellungen zu lösen. Um das zu tun, muss man sich bloß ein bestimmtes Programm installieren, dass auf einem Computer läuft der möglichst oft/dauerhaft betrieben wird. Wer also z.B. zuhause einen Raspberry Pi oder so wie ich, sowieso einen Server betreibt, kann wissenschaftliche Arbeit leisten in dem er teile seiner freien Prozessorkapazität zur Verfügung stellt.
Hinweis
Vor einem Betrieb auf einem Laptop oder einem klassischen PC sollte man bedenken, dass durch erhöhten CPU-Verbrauch die Lebensdauer, wenn vielleicht auch nicht signifikant, heruntergesetzt bzw. der Stromverbrauch gesteigert wird. Von einem Betrieb auf Cloud-Server Angeboten wie Microsoft Azure oder Amazon AWS, ist wegen der auf CPU-Leistung und Datenübertragung basierenden Abrechnungsmodelle, ebenfalls abzuraten. Sonst kann es teuer werden!
Was ist Boinc?
Die Schaffer des Tools Boinc haben es sich zur Aufgabe gemacht ca. 30 wissenschaftliche Volunteer-Computing Projekte über eine Oberfläche verfügbar und konfigurierbar zu machen. Auch Einstellungen wie die zur Verfügung zu stellenden Ressourcen und Reports über bereits geleistete Arbeit stellt das Tool zur Verfügung. Eine genaue Liste mit Beschreibung der Projekte findet sich hier: https://boinc.berkeley.edu/projects.php . Dort wird auch schon ersichtlich, dass nicht jedes Projekt für jede Computerplattform existiert und andere nicht für jede Art von Plattform geeignet sind. So benötigen einige von Ihnen z.B. eine schnelle dezidierte Grafikkarte, da die angestellten Berechnung auf diesen Prozessortyp (GPU) optimiert sind.
OK, gefällt mir. Wie starte ich?
Die Installation kann entweder manuell und direkt über das auf der Boinc Homepage verfügbare Installationsprogramm erfolgen oder, wie von mir bevorzugt und folgend beschrieben, als Docker Container mit Docker Compose.
Die manuelle Installation funktioniert auf jeder Art von Rechner und kann zum Beispiel so konfiguriert werden, das BOINC als Bildschirmschoner läuft und so nur dann Ressourcen des PCs beansprucht, wenn dieser gerade nicht genutzt wird. Die Installation kann man unter https://boinc.berkeley.edu/download.php herunterladen.
Für den Betrieb auf einem Server in einem Container hier eine beispielhafte docker-compose.yml Datei:
Die Angabe der zur Verfügung gestellten Ressourcen über deploy – resources – limits, ist optional. Eine Beschränkung der dem Program bereitgestellten Ressourcen lässt sich, wie schon zuvor erwähnt, auch direkt im Programm konfigurieren. Ich gehe hier auf Nummer sicher und schränke den Zugriff von vorn herein ein. Ein CPU Wert von 1 entspricht einem CPU-Thread. Bei z.B. vorhandenen 8 Threads, kann der hier definierte Container also auf 12,5% der verfügbaren CPU-Leistung zugreifen. Genau das von mir gewünschte “Grundrauschen”. Die Angabe des Ports ist nur erforderlich, wenn wir keinen Reverse Proxy nutzen. Dann wäre unsere BOINC Instanz auf dem Host über den entsprechenden Port erreichbar. Das Passwort sollte auf jeden Fall gesetzt werden und ist dann zur Anmeldung am virtuellen Desktop über den Browser erforderlich. Der Benutzer ist übrigens fest auf abc eingestellt.
Anwendung und Fazit
Entweder durch starten der Anwendung oder durch Zugriff auf das Webinterface im Conatinerbetrieb, können wir uns nun im Program für die Projekte die uns intressieren anmelden und die Prozesse starten. Danach passiert eigentlich nichts spannendes mehr und eine weiteres Eingreifen unserseits ist nicht erfordlich. Unseren Beitrag zum jeweiligen Projekt können wir über die im Program integrierten Berichte oder auf der jeweiligen Projektseite jederzeit einsehen. Dort oder unter können wir uns auch ein Zertifkat gennerieren lassen, wenn wir das möchten.
MS Teams und Co. sind jetzt schon seit einigen Jahren täglicher Begleiter durch das Berufslebeben und haben den Büroalltag mehr als ergänzt. Möchte man auch im virtuellen Besprechungsraum ein wenig Individualität und Kreativität zeigen, geschieht das meistens durch ein ausgefeiltes Hintergrundbild. Aber dann sind da noch die Kollegen die besonders herausstechen, indem sie mit bewegeten Hintergrundanimationen und Interaktivität aufwarten. Wie machen die das? – Gerade MS Teams lässt doch gar keine animierten Hintergründe zu, sondern akzeptiert nur statische Bilddateien wie jpgs und pngs! Um selbst in den Genuss von animierten Hintergründen in einer MS Teams Besprechung zu kommen, gibt es grundsätzlich zwei Wege:
Einsatz einer Software eines Drittanbieters, wie OBS Studio & Co., sowie ggfs. weiteren Accessoires, wie einem Greenscreen.
Oder ganz einfach; mit einem kleinen Trick mit dem sich MS Teams überreden lässt auch animierte Hintergründe zu verwenden 🙂 Dieses Tutorial bechreibt wie wir aus einer z.B. in PowerPoint generierten Animation, ein bewegtes Hintergrundbild erzeugen und dieses in MS Teams implantieren.
Die animierte PowerPoint Datei
Was wir benötigen ist eine GIF Datei, ein animiertes Bild. Ein solches lässt sich mit einer Vielzahl von Werkzeugen erstellen, PowerPoint ist also nur eine von vielen Möglichkeiten. Zunächst erstellen wir eine neue Folie und darin dann wie gewohnt die gewünschte Animation. Sobald wir mit unserem Ergebnis zufrieden sind, exportieren wir die Folie als “gif” Datei.
Unser Trick
In unserem Beispiel gehen wir davon aus, dass unsere exportierte GIF Datei folgenden Namen trägt: hintergrund.gif Der ganze Trick liegt jetzt darin diese Datei zweimal zu kopieren und die zwei neuen Dateien hintergrund.jpg hintergrund_thumb.jpg zu nennen. Das führt zwar eigentlich zu zwei ungültigen Dateien, aber so lässt sich MS Teams dazu überreden diese zu “schlucken”.
Integration in MS Teams
Wir sind schon fast fertig. Jetzt beenden wir MS Teams am besten, falls es gerade geöffnet ist. Die beiden zuvor generierten Dateien müssen wir nun nur noch in einen bestimmten Ordner auf unserem PC oder Mac verschieben.
Windows Benutzer können im Windows-Suchfeld %appdata% eingeben und sich dann in folgenden Unterordner “hangeln”: %APPDATA%\Microsoft\Teams\Backgrounds\Uploads Um die Dateien dort abzulegen.
Und Mac User gehen über den Finder unter “Gehe zu” -> “Gehe zum Ordner” nach: /Users/BENUTZER/Library/Application Support/Microsoft/Teams/Backgrounds/Uploads Wobei die Variable “BENUTZER” im Pfadnamen natürlich durch unseren Benutzernamen zu ersetzten ist.
Jetzt können wir MS Teams wieder starten und unseren neuen animierten Hintergrund wie gewohnt bei der Auswahl der Hintergrundfilter selektieren!
In einer besonders unglücklichen Situation bin ich kürzlich von einem Freund kontaktiert worden: Er hat sein Windows 10 Anmeldepasswort unwiederbringlich vergessen. Also auf zu Google und siehe da; es gibt unzählige Lösungsvorschläge um ein Win10 Passwort zurückzusetzen. Dann aber die Ernüchterung: Microsoft hat schon nachgebessert und alle Tricks, die ich gefunden habe, funktionieren leider nicht mehr. Was nun?
Zeit für Eigeninitative 🙂 In dieser Anleitung beschreibe ich in Kürze, wie man ein Administratorkonto, auch in der aktuellsten Windows 10 Version, zurücksetzen kann.
So viel im Voraus: Microsoft muss hier weiter nachbessern, denn die beschriebene Methode kann dazu genutzt werden administrativen Zugriff auf jegliche Win10 PCs zu erlangen. Einzige Vorraussetzung ist der physische Zugriff auf den Rechner.
Vorbereitung
Mein Freund hat mir den betroffenen Computer vorbeigebracht, also hatte ich direkten Zugriff auf den Rechner. Das Benutzerkonto auf das er nicht mehr zugreifen konnte, war ein lokales Konto.
Hinweis: Für ein Benutzerkonto, dass mit der Microsoft Cloud verknüpft ist, funktioniert diese Anleitung nur teilweise – Dort ist das zurücksetzen des Passworts aber auch kein Problem und kann von einem anderen Endgerät aus, Online erledigt werden.
Außerdem habe ich mir ein Windows 10 Installationsmedium auf einem USB-Stick erzeugt, weil ich während der ersten Recherechen darauf gestoßen bin, dass das erforderlich ist. Den offiziellen Windows 10 Download findet man unter in den Quellen am Ende des Artikels. Zum erstellen des Sticks brauchen wir natürlich irgendwo einen zweiten Rechner auf den wir Zugriff haben. Die heruntergeladene ISO Datei lässt sich je nach Betriebssystem unterschiedlich auf den Stick bringen. Google hilft.
Vorgehensweise
Folgende Schritt-für-Schritt Anleitung umreißt die als funktionierend gestestete Vorgehensweise um das Passwort eines lokalen Windows 10 Benutzers zurückzusetzen.
Zunächst booten wir von unserem zuvor erzeugten Bootstick.
Im ersten Dialogfenster der Sprachauswahl etc. drücken wir gleichzeitig die SHIFT + F10 Tasten.
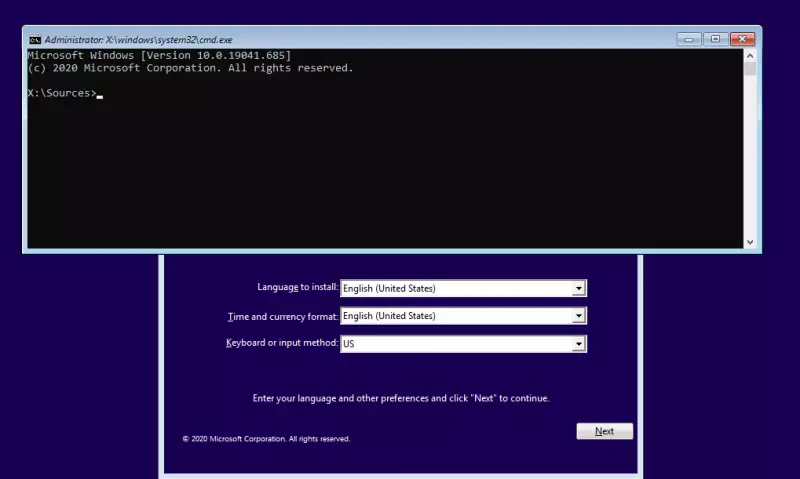
In der daraufhin erscheinenden Kommandozeile (oha; dass dürfte doch eigentlich gar nicht funktionieren), wechseln wir auf die Partition unserer lokalen Windows 10 Installation, also z.B. mit den Befehl “C:”.
Nun “hangeln” wir uns ins lokale Systemverzeichnis. Das geht z.B. mit den Befehlen: “cd Windows” Enter Taste, dann “cd system32” Enter Taste.
Jetzt erstellen wir unser “magisches Tor” um später, beim normalen Hochfahren, ebenfalls in die Kommandozeile wechseln zu können. Mit “cp utilman.exe utilman_old.exe” sichern wir zunächst den Eingabehilfeassistenten um ihn später wiederherstellen zu können.
Mit “copy cmd.exe utilman.exe” erzeugen wir eine Kopie des Kommandzeilenprogramms unter dem Namen des Eingabehilfeassistenten.
Das war der erste Streich. Wir können nun die Windows Installationsroutine schließen und den Rechner wieder normal hochfahren.
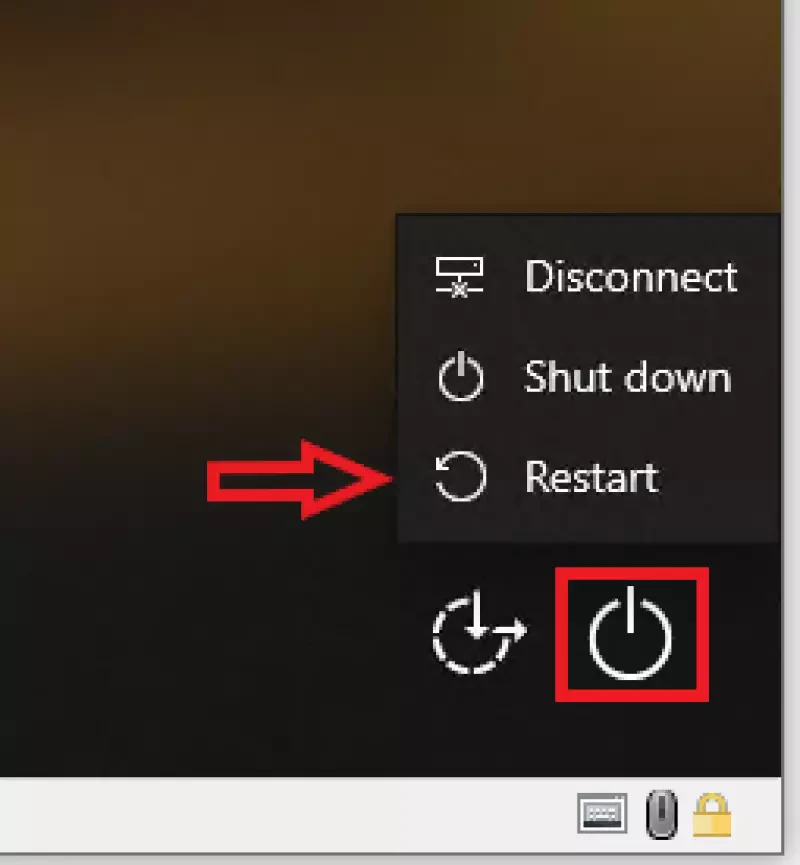
Wir müssen am Anmeldebildschirm einen erneuten Reboot im abgesicherten Modus herbeiführen, da zumindest mir, sonst Aufrufe der Kommandozeile blockiert wurden (vermutlich vom im Hintergrund laufenden Systemschutz-Program…). Also die “SHIFT” Taste gedrückt halten, unten Rechts auf das Powersymbol drücken und Neustart auswählen.
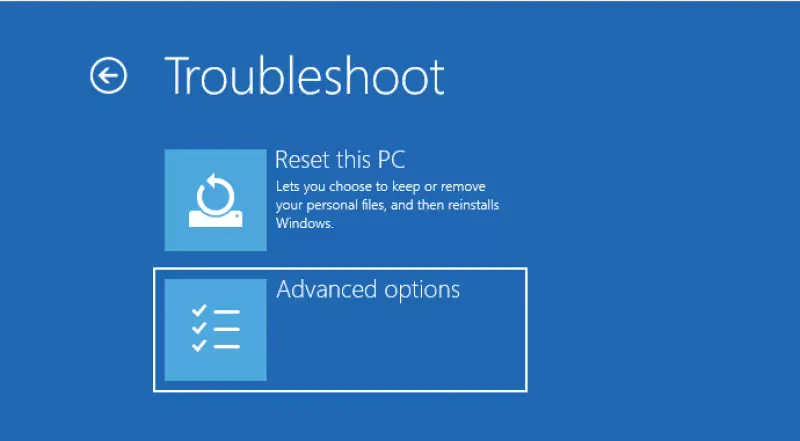
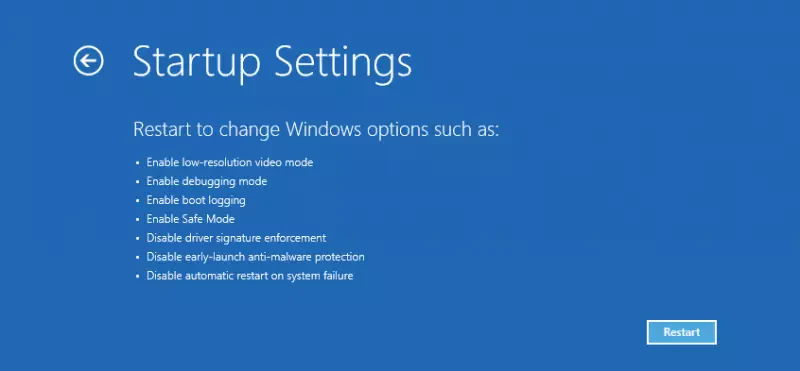
Im nach kurzer Zeit erscheinenden Zwischendialog wählen wir “Advanced Options” bzw. “Erweiterte Optionen”, und dann “Startup Settings” bzw. “Starteinstellungen”. Nun auf “Restart” bzw. “Neustart” klicken. (Sorry, habe gerade nur Englische Screenshots)
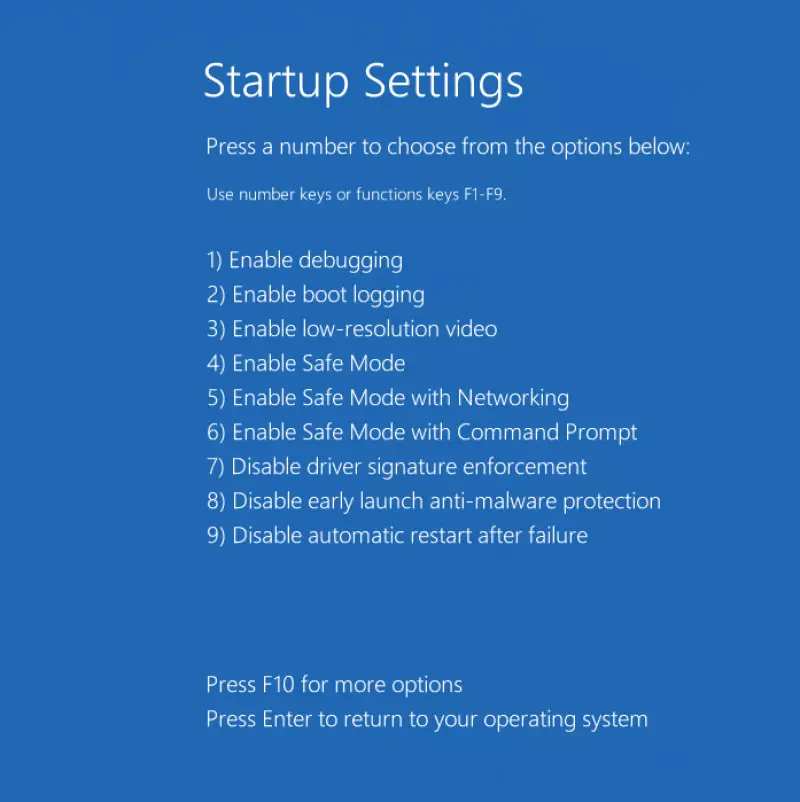
Sobald der Rechner wieder oben ist, drücken wir die Taste 6 um den abgesicherten Modus mit Kommandozeile zu starten.
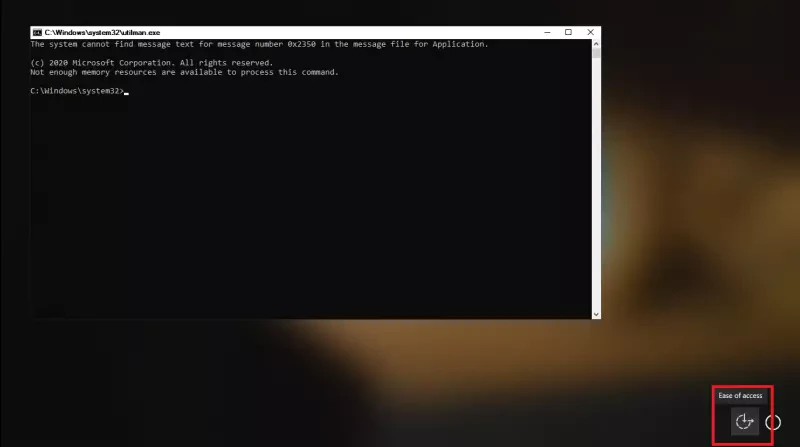
Leider startet sich die Kommandozeile nicht direkt, da wir zunächst unser Passwort eingeben sollen (haha), aber unser Trick den wir durch Schritt 6 ermöglicht haben, kann nun ausgeführt werden: Wir klicken auf das Symbol für die Eingabehilfe (das zweite Symbol rechts unten) und Voilà: Die Kommandozeile öffnet sich, und dieses mal mit vollen Berechtigungen!
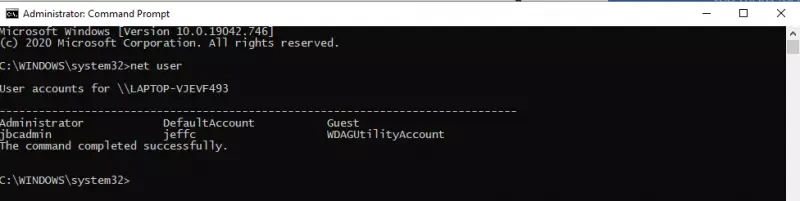
Durch Eingabe des Befehls “net user”, bekommen wir eine Liste aller lokalen Benutzerkonten angezeigt. Da fehlt mir anscheinend das Know-How, aber das Benutzerkonto um das es mir eigentlich geht, wird gar nicht angezeigt?! Macht nichts: Wir reaktivieren einfach das vorhandene “Administrator” Benutzerkonto und arbeiten mit diesem weiter. Wie? nächster Schritt:
Der Befehl “net user Administrator /active:yes” aktiviert das Konto und der Befehl “net user Administrator PASSWORD” setzt das Passwort PASSWORD für diesen. (mit angepassten Befehlen lässt sich so natürlich auch ein komplett neuer User als Admin einrichten, falls der User “Administrator” nicht verfügbar ist.)
Weil es so schön ist: Zeit für einen Reboot
Im Anmeldebildschirm unten links sehen wir nun mehrere Benutzer zur Auswahl, und eben auch den “Administrator” den wir soeben aktiviert haben. Auf diesen klicken wir jetzt und melden uns dann als dieser User am System, mit dem zuvor gestetzten Passwort, an.
Nachdem wir die Windows “Ersteinrichtungshölle” hinter uns gelassen haben, sehen wir jetzt einen mehr oder weniger augeräumten Desktop und haben uns erfolgreich mit Adminstratorberechtigungen angemeldet!
Jetzt können wir über die Systemsteuerung -> Benutzer -> Andere Konten das Passwort unseres eigentlichen Benutzer komfortabel ändern und ja; den PC neu starten.
Fertig: Jetzt können wir im Anmeldebildschirm von Windows wieder unseren eigentlichen Benutzer auswählen und uns mit dem neu gesetzten Passwort anmelden.
Aufräumen
Unsere gesetzten Spuren machen wir über folgende Befehle in der Windows Kommandozeile wieder rückgängig:
“net user administrator /active:no” – Wir deaktivieren den “Administrator” Benutzer wieder, brauchen wir nun ja nicht mehr.
“C:”, “cd Windows”, “cd system32”, “del utilman.exe”, “copy utilman_old.exe utilman.exe” – stell die Systedateien wieder auf ihren ursprünglichen Zustand.
Fazit
Um dem gestellten Problem von vornherein aus dem Wege zu gehen, könnte man z.B. ein Microsoft Account (wenn man dem Unternehmen traut) erstellen und mit dem Konto verknüpfen. Dann ist das zurücksetzen evtl. Online möglich, insofern der betroffene PC eine Internetverbindung hat.
Auch kann man mit kürzeren PINs arbeiten, die Microsoft seit geraumer Zeit für das Anmelden, neben der weiteren Option eines Erinnerungssatzes, bereitstellt.
Nichtsdestotrotz (ja, das schreibt sich wohl so): Mit der beschriebenen Vorgehensweise lässt sich nicht nur ein vergessenes Windows Passwort zurücksetzen, sondern auch Zugriff auf jeden Windows 10 PC, auf den physischer Zugriff besteht, beschaffen. Eine eklatante Sicherheitslücke die in anderen Betriebssystemen wie Linux und MacOS besser “gestopft” ist.
Naja, meinem Freund konnte ich so jedenfalls helfen 🙂
Nachtrag: Wie kann ich mich vor so einem “Angriff” schützen?
Eigentlich dürfte das beschriebene Szenario überhaupt nicht funktionieren, weil sich so jeder administrativen Zugang auf einen Windows PC verschaffen kann.
Ursache ist eine Verkettung von Umständen, die uns diese Sicherheitslücke öffnet. Um solch einen Angriff zu verhindern reicht es nicht aus, einfach auf ein Micorosoft Online Konto zu wechseln. Es kann sich ja trotzdem jeder über ein neues Benutzerkonto administrativen Systemzugriff verschaffen, sobald sie/er physischen Zugriff auf den Rechner hat.
Einen solchen Angriff zu verhindern ist nicht trivial, denn folgendes müsste in Kombination gemacht werden:
Setzen eines Passworts auf BIOS Ebene: Verhindert den Start eines anderen Bootmediums und ähnliches. Das werden viele aus Bequemlichkeit nicht machen wollen.
Aktivieren der Festplattenverschlüssung, z.B. mit Bitlocker: Sonst könnte man die Festplatte einfach aus dem Rechner herausschrauben/löten und den Inhalt woanders auslesen. Kontra: Das macht den Windows PC (noch) langsamer.
Microsoft selbst könnte wiederum nachbessern indem Sie in Windows:
den Zugriff auf die Kommandozeile während der Installationroutine unterbinden. Vermutlich ist das nicht so einfach umzusetzen, da die Kommandozeile hier und da ebenfalls für Spezialfälle benötigt werden könnte.
die Signaturen von Systemdateien, die vor dem erfolgreichen Login ausgeführt werden, prüfen. Das sollte sich auf jeden Fall umsetzen lassen und es ist verwunderlich das Microsoft das nicht schon lange tut. Unter Linux gibt es dafür schon seit Jahren Implementierungen wie z.B. SELinux.
Docker hilft uns durch sogenannte Container dabei die technische Serverinfrastruktur, die für verschiedenste Projekte benötigt wird, schnell und vom Basissystem isoliert aufzusetzen. Außerdem veringern wir durch den Einsatz von Docker den Wartungsaufwand z.B. für Systemaktualsierungen und Backups. Tausende von Projekten stehen vorgefertigt zur Verfügung, die mit einem einfachen Kommando nur gestartet werden können. In diesem Artikel beschreibe ich wie Docker und das zusätzlich hilfreiche Docker Compose installiert werden. Docker Compose hilft uns dabei ganze Containerlandschaften zur orchestrieren. Ein Beispiel: Bei der Installation von WordPress über Docker werden mehrere Container benötigt, einer für die App und einer für die Datenbank. Wenn wir diese nun alle einzeln starten und evtl. dabei noch bestimmte Parameter übergeben wollen, wird es schnell uünbersichtlich. Mit Compose können wir alle benötigten Parameter und Container in einer strukturierten Datei zusammenfassen und diese Umgebung mit einfachen Befehlen steuern.
Vorraussetzungen
Wir gehen davon aus, dass wir ein Linuxsystem auf Basis von Debian als Betriebssystem nutzen. Das können z.B. das Raspberry Pi OS, Ubuntu oder eine der vielen anderen Varianten davon sein. Grunsätzlich funktioniert Docker aber auch unter allen anderen Linux Systemen und auch unter Windows oder MacOS.
Am Besten handelt es sich um frisch installiertes System auf dem sonst nichts weiter läuft. Das ist aber nicht zwingend erforderlich. Wir sind entweder direkt über einen Terminal oder via SSH am Server als unser Benutzer (nicht root) angemeldet.
Installation von Docker und Docker Compose
Wir wollen immer die aktuellsten Versionen nutzen und orientieren uns deshalb an den Anleitungen auf den offiziellen Docker Seiten dazu.
Wenn man sich nicht von der augeinscheinlich großen Masse der Schritte erschlagen lässt, sehen wir dass wir im Endeffekt nur 3-4 Kommandos per Copy & Pase in unsere Kommandozeile kopieren mussten.
Am besten führen wir abschließend noch einmalig einen Reboot unseres System durch.
Verwendung von Docker Compose
Der Aufbau einer Docker-Composse Konfiguration ist im endeffeckt immer gleich und basiert auf einer einzelnen Datei, der docker-compose.yml. Diese legt man am besten nicht einfach irgendwo hin, sondern überlegt sich eine Ordnerstruktur, da man ja evtl. viele Umgebungen parallel betreiben und den Überblick behalten möchten. Ein Beispiel:
wir legen im Verzeichnis /opt/ ein Unterverzeichnis /opt/docker/an.
Und hier dann wiederum Unterverzeichnisse z.B. nach Projekten oder URLs gegliedert. Also zum Beispiel /opt/docker/wordpress/.
In dieses Untervzeichnis gehört dann unsere Datei zur Definition der Umgebung, also /opt/docker/wordpress/docker-compose.yml
Wenn wir beim Beispiel WordPress bleiben bekommen wir auf https://hub.docker.com/_/wordpress ein Beispiel für den Inhalt der docker-compose.yml
Dieses Beispiel wollen wir noch etwas für uns anpassen und für den dauerhaften Betrieb optimieren. Das kann dann so aussehen (Achtung die Formatierung mit den freien Zeichen als Tabs ist bindend):
service, container_name, hostname: Nur den Service selbst zu benennen ist Pflicht. Die anderen beiden Variablen setzen wir um unseren Container je nach Zugriffsart schnell finden zu können, wenn wir ihn mal suchen.
restart: always bedeutet, dass der Container neu gestartet wird, egal warum auch immer er zuvor abgebrochen/abgestürzt ist.
environment: Verschiedene Umgebungsvariablen die an den Container weitergegben werden. Das können je nach Image ganz unterschiedliche sein.
volumes: Persistente Daten, die wir z.B. auch für ein Backup berücksichtig bzw. grundsätzlich unter unserer Kontrolle haben und nicht im Container “versteckt” haben wollen. durch ./bestimmen wir, dass es sich dabei um einen Uneterverzeichnis des aktuellen Ordners handelt. Falls nicht vorhanden würde dieser automatisch angelegt werden, besser aber vorher schon selber anlegen (Berechtigungen, etc…).
logging: Manche Container/Applikationen sind recht freudig im Schreiben von Protokolldateien. Hiermit schränken wir dies auf 3 10MB große Dateien ein, wobei der älteste Eintrag beim überschreiten der Grenze überschrieben wird.
ports: Falls kein Reverse Proxy zum Einsatz kommt, gibt z.B. 8080:80 an, dass der im Container laufende Port 80 and das Host System unter Port 8080 weitergleitet wird. D.h. wenn wir in unserem Beispiel WordPress aufrufen möchten, dann mit: http://HOST:8080 . Zur Kommunikation der Container Untereinander also z.B. von App zur DB wird keine Portfreigabe benötigt! Das erhöht die gleichzeitig die Sicherheit unserer Umgebung.
Nützliche Befehle
Aus dem Verzeichnis heraus, in dem wir unsere docker-compose.yml angelegt haben können wir unsere Umgebung nun mit docker compose up -d starten. Wenn wir alle Container aus der Compose Datei herunterfahren möchten, geht das mit docker compose down. Mit dem Befehl docker compose pull ziehen wir die aktuellste Version unserer Images von Docker Hub. Nach dem Pull ist ein erneutes docker compose up -d erforderlich um die Container in der neuen Version zu starten. Die persistenten Daten aus den definierten Volumes bleiben dabei natürlich erhalten. Gefährlich wird es nur bei größeren Versionssprüngen innerhalb der Anwendung. Dann gibt es entweder die Möglichkeit die Umgebung herunterzufahren, das letzte geladene Image zu löschen und dann wieder zu starten. Alternativ lässt sich in der docker-compose.yml auch eine version des Images fest einstellen. Damit verzichtet man in der Regel aber auch Sicherheitsupdates.
Universalfernbedienung? Mehr 90er geht es ja nicht! Was aber wenn die alte Infrarot Fernbedienung alle Lichter im Raum ein- und ausschalten, die Heizung oder Rollos bedienen und das Heimkino gleichzeitig steuern kann? Dieser Beitrag hat es in sich, denn auf diese Art lässt sich jedes irgendwie auslesbare/anbindbare Gerät in euer Alexa, HomeKit oder nahezu jede andere Smart Home Lösung integrieren! Das alles ohne Abos, versteckte Kosten und auf Wunsch auch ganz ohne die Cloud irgendeines großen Konzerns.
Zielsetzung
In dieser kleinen Aufbauanleitung beschreibe ich wie ich aus mehreren Komponenten ein IoT (Internet of Things) Szenario aufgebaut habe. Ein grundsätzliches technisches Verständnis hilft dabei die einzelnen Schritte nachzuvollziehen, ein IT-Studium oder eine ähnliche Ausbildung ist aber definitiv nicht erforderlich!
Das Ziel ist es mit einer handelsüblichen (gerne auch aus dem untersten Preissegment, oder noch besser: Elektroschrott) Infrarot Fernbedienung verschiedene Aktionen in einem Smart Home auszulösen. Ich will von einer einfachen Hardwareumgebung aus, beim Eintreffen eines Infrarotsignals, dessen Eingabewerte an meine Heimautomatisierung übergeben.
Als Hardware nutzen wir den kleinen Bruder des weltberühmten Raspberry Pi, den Zero W und wenig weiteres Zubehör. Alles davon kann auch ohne Mühen für andere Zwecke genutzt werden. Dank tausenden von verfügbaren “Bastelanleitungen” im Netz ist die eventuelle Neuanschaffung auf keinen Fall umsonst.
Bei der Software wähle ich wie immer möglichst ausschließlich Open Source Quellen, wie z.B. Linux und Node-RED. Die gigantische Community dahinter leistet uns eine 24/7 Unterstützung bei jeglicher Art von Problemstellung.
Hardware
Viel mehr als in der Zielsetzung beschrieben braucht es wirklich nicht. Falls du die Komponenten nicht herumliegen hast, hier zunächst ein paar Kaufempfehlungen.
Ab ca. 16 € gibt es den Kleinstcomputer Raspberry Pi Zero W mit passendem Gehäuse z.B. hier: https://www.berrybase.de/raspberry-pi/raspberry-pi-computer/kits/raspberry-pi-zero-w-zusammenstellung-zero-43-case. Der Zero ist für unseren Zweck besonders gut geeignet, weil wir zum einen keine besonders große Leistung benötigen, zum anderen aber Strom sparen wollen. Denn wir planen einen Dauerbetrieb. Mit einer Spannung von 2,3 bis 5,0 V und einer Stromstärke von 100 bis 140 mA, müsste der tatsächliche Stromverbrauch zwischen 0,23 Watt und 0,7 Watt liegen. Das ist weniger als so mancher Fernseher im Standby “frisst”. Das klingt vielleicht alles super “billig”, winzig und schwach, aber: Es ist 2021 und das bisschen Hardware hat die gleiche Rechenleistung wie ein Spitzen-Heimcomputer kurz nach der Jahrtausendwende. Und Windows XP wollen wir ja gar nicht installieren… Damit der Raspberry funktioniert braucht es noch Strom, am besten aus einem alten Handynetzteil mit Micro-USB Anschluss. Falls gerade keines verfügbar ist, bekommt man so etwas Überall für wenige Euro, so z.B. auch im Supermarkt. Hinzu kommt noch eine Micro-SD Karte, die vielleicht auch noch irgendwo zuhause herumliegt. Alles ab 8GB Größe ist OK, nur sollte sie über den Zusatz “XD” oder “HC” verfügen, damit man sicher ist nicht eine “lahme Ente” zu verwenden. Da geht es bei ca. 3 € los und auch hier wird man in den meisten Supermärkten fündig. Ein kleines Adapterkabel hilft uns Geräte mit normalgroßem (Typ A) USB-Anschluss, wie den Infrarotempfänger, mit dem Raspberry Pi Zero zu verbinden. Das wiederum wird man eher selten im Supermarkt finden, aber z.B. hier: https://www.berrybase.de/raspberry-pi/raspberry-pi-computer/kabel-adapter/usb-kabel-adapter/usb-2.0-hi-speed-otg-adapterkabel-a-buchse-micro-b-stecker-0-15m-wei-223. Und damit ist man weitere 1,80 € ärmer. Wer nun über gar keine dieser Komponenten verfügt, kann sich auch ein Komplettset besorgen, z.B. hier: https://www.berrybase.de/raspberry-pi/raspberry-pi-computer/kits/raspberry-pi-zero-w-zusammenstellung-full-starter-kit Um die SD-Karte später mit dem Betriebssystem bespielen zu können, brauchen wir noch ein SD-Kartenleser. Die meisten Laptops haben einen solchen integriert. Aber falls nicht, gibt es die auch günstig ab 5€ fast überall und z.B. hier: https://www.heise.de/preisvergleich/sandisk-mobilemate-single-slot-cardreader-sddr-b531-gn6nn-a2356696.html
Bei der Fernbedienung hat man die Qual der Wahl. Wirklich jegliche Art von Gerät, das ein Infrarotsignal sendet, kommt hier in Frage. Es sollte natürlich keine genommen werden, die zu einem aktiv benutzten Gerät im gleichen Raum gehört, aber das versteht sich hoffentlich von selbst. Ich habe eine alte Universalfernbedienung benutzt, die ich noch übrighatte. Damit habe ich es mir selbst einen kleinen Tick schwieriger gemacht als nötig, da ich diese nun auf ein nicht vorhandenes Empfangsgerät voreinstellen musste. Einfacher wäre es gewesen, wirklich eine ganz “normale” zu verwenden.
Zum Schluss noch der Infrarotempfänger. Das ist tatsächlich fast die größte Investition hier im Projekt. Ich hatte noch den, qualitativ hochwertigen und mit cleverer Softwarelösung kommenden, FLIRC USB-Empfänger. Den bekommt man z.B. hier: https://www.heise.de/preisvergleich/flirc-usb-rev-2-flirc-v2-a1621664.html, ab ca. 24 €
Alles in allem also eine Investition zwischen 0€ und maximal 65€ Euro.
Software
Nun zum zumindest für Anfänger komplizierten Teil, aber immerhin: viel Software braucht es nicht. Eigentlich nur ein Betriebssystem und zwei zusätzliche Programme/Tools. Da sich die Fernbedienung am einfachsten über eine Desktopumgebung konfigurieren lassen wird, installieren wir diese auf unsere SD-Karte. Das geht mittlerweile maximal einfach. Unter https://www.raspberrypi.org/software/ gibt es das Programm “Raspberry Pi Imager”, welches ihr dort für euer Betriebssystem herunterladen könnt. Vor dem Öffnen des heruntergeladenen und installiertem Programms steckt ihr noch die SD-Karte in euren SD-Karten-Lesegerät bzw. -slot. Im Programm wählt ihr dann das Betriebssystem “Raspberry PI OS (32-Bit)” aus, und als SD-Karte die eurige. Mit einem Klick auf “SCHREIBEN” wird das Betriebssystem auf eure Karte kopiert.
Sobald der Vorgang abgeschlossen ist, entfernt ihr die Karte bitte noch NICHT. Denn wir wollen zuvor noch zwei Dinge erledigen, die uns das Leben anschließend erleichtern. Falls schon, vor Ungeduld oder welchem Grund auch immer, herausgezogen ist das auch kein Problem, einfach wieder rein damit. Zunächst erstellen wir im Hauptverzeichnis der SD-Karte eine, gerne auch leere, Datei mit dem Namen “ssh”. Bitte achtet darauf, dass die Datei keine versteckte Endung wie z.B. “.txt” hat. Das passiert gerne unter den Standardeinstellungen von Windows. Mac und Linux Anwender haben dieses Problem in der Regel nicht. Wem das zu ungenau beschrieben ist, der guckt bitte hier: https://www.shellhacks.com/raspberry-pi-enable-ssh-headless-without-monitor/.
Jetzt möchten wir noch gleich die Verbindungsdaten zu unserem WLAN angeben, damit die Netzwerkverbindung von Anfang an sichergestellt ist. Dazu legen wir eine zweite Datei Namens “wpa_supplicant.conf” in das Gleiche Verzeichnis. Windows Benutzer passen wieder bei der Dateiendung auf. Dieses Mal kommt es aber auf den Inhalt der Datei an:
Das ist nur ein Beispiel, und wir müssen die Werte in den Klammern bei den Zeilen “ssid” und “psk” auf die Werte unseres WLANs setzen.
Jetzt sind wir aber fertig und die Karte kann entfernt und in den Raspberry gesetzt werden. Nun steckt ihr alle Komponenten zusammen und bringt das Ganze an seinen Bestimmungsort. Sobald ihr das Gerät mit dem Netzteil verbunden habt, seht ihr:
Erstmal nicht viel.
Kein Grund zur Panik, das ist normal und ihr habt vermutlich alles richtig gemacht. Wir machen einfach weiter.
Wir sind jetzt in der Lage uns per SSH auf dem kleinen Raspberry anzumelden, um dort ein paar Dinge einzustellen. Um sich kurz auf Kommandozeilenebene die Finger schmutzig zu machen, kommen wir leider nicht herum und leider lässt sich dafür im Falle des Raspberry Pi Zeros auch nicht Visual Studio Code verwenden. Ein Terminal muss her.
Unter MacOS und Linux ist eine Terminal Applikation für die Kommandozeile seit je her eingebaut und heißt dort auch so. Soweit ich weiß, steht das SSH Kommando auch in Windows 10 zur Verfügung, kann das aber leider gerade nicht testen. Allen die damit nicht vertraut sind, hilft Google gerne weiter. Die Verbindung zu unserem neuen Kleinstcomputer stellen wir dann wie folgt her:
ssh pi@192.168.178.22
Die IP-Adresse muss natürlich auf die eures Raspi angepasst werden. Die bekommt ihr am schnellsten über das Webinterface eures Routers heraus. Das Standardpasswort nachdem ihr nun gefragt werdet ist: raspberry . Wenn ihr das nach der Anmeldung gleich ändern möchtet, geht das mit dem Befehl “passwd”. Es empfiehlt sich Betriebssystem und Software regelmäßig auf den neuesten Stand zu bringen, das macht man mit den Befehlen:
sudo apt-get update
um aktuell verfügbare Pakete zu ermitteln, um diese dann wiederum mit:
sudo apt-get upgrade
zu installieren. Jetzt installieren wir Node-RED mit dem Befehl:
und wenn wir schon dabei sind, bestimmen wir noch, dass Node-RED bei jedem Systemstart automatisch gestartet wird:
sudo systemctl enable nodered.service
Nun starten wir das System am besten einmal neu. Das geht mit:
sudo reboot
Nach spätestens 3-4 Minuten sollte alles wieder hochgefahren sein und wir müssten in der Lage sein auf Node-RED, über den Browser eines beliebigen Gerätes in eurem Netzwerk, zuzugreifen:
https://192.168.178.22:1880
Auch hier die IP-Adresse durch die eures Raspis ersetzen. Wenn sich nun die Weboberfläche von Node-RED öffnet, können wir unseren ersten Erfolg feiern. Wir haben aus unserem kleinen Raspi ein mächtiges IoT Werkzeug gemacht!
Jetzt wollen wir uns daran machen unsere Fernbedienung zu konfigurieren. Dafür müssen wir noch einmal die Kommandozeile bemühen und uns wie zuvor beschrieben auf den Raspi schalten. Als Erstes prüfen wir, ob uns der Desktop des Raspis später zur Verfügung stehen wird. Wie das geht, ist perfekt hier: https://www.raspberrypi.org/documentation/remote-access/vnc/ beschrieben. Dort auf den Abschnitt “Enabling VNC Server at the command line” fokussieren, den Rest können wir für den Moment ignorieren.
Auch auf Kommandozeilenebene installieren wir die grafische Oberfläche für unseren Flirc Infrarotempfänger. Das geht mit (copy & paste):
curl apt.flirc.tv/install.sh | sudo bash
Jetzt haben wir alles zusammen was wir brauchen und können endlich mit dem richtigen Spaß beginnen.
Konfiguration
Verglichen mit der Softwareinstallation, ist die eigentliche Konfiguration nun ein “Klacks”.
Im ersten Schritt lernen wir unsere Fernbedienung an. Dazu schalten wir uns per VNC auf den Desktop des Raspberry PI Zero. Dort öffnen wir dann das Programm Flirc, welches wir im Startmenü finden. Bevor es losgeht, stellen wir die Ansicht noch auf “Keyboard” um. Dadurch stehen uns schon ohne Tastenkombinationen mehr als 127 Kommandos (Tasten) zur Verfügung, die wir auf unserer Fernbedienung belegen können. Da wir niemals eine echte Tastatur an den Raspi anschließen werden, ist das Einzige, worauf wir achten müssen, dass wir keine Sondertasten belegen. Die “Drucken” Taste zu belegen ist also keine gute Idee, alle Zahlen und Buchstaben: kein Problem. Um die Belegung zu starten, klicken wir im Programm auf eine der angezeigten Tasten, also z.B. “F”. Dadurch werden wir nun aufgefordert unsere Fernbedienung in Richtung des Infrarot Empfänger zu halten und darauf ebenfalls einen Knopf zu drücken. Dieses Prozedere spielen wir für alle Knöpfe auf unserer Fernbedienung durch, die wir später mit einer Aktion hinterlegen wollen. Jetzt ist unsere Fernbedienung “angelernt” und wir können die VNC Session wieder beenden. Das FLIRC Programm kann vorher auch beendet werden, es läuft im Hintergrund weiter und unsere Kommandos stehen auch nach einem Neustart weiterhin zur Verfügung.
Ab hier darf jetzt Node-RED zeigen was es kann. Und das Programm macht es uns maximal einfach! Wir öffnen wieder im Browser eines beliebigen Endgeräts unseres Netzwerks die Node-RED GUI:
https://192.168.178.22:1880
Unser Flow (Ablauf) benötigt nur zwei Knoten aus dem “Standardsortiment”. Als erstes ziehen wir aus der linken Leiste einen “rpi – keyboard” Knoten in den Flow. Der macht nichts anderes als, wie der Name es erahnen lässt, auf Tastatureingaben am Raspi zu lauschen. Durch unsere Konfiguration von FLIRC hört er so automatisch auch auf die Eingaben unserer Fernbedienung. Wer das Testen oder einfach sehen möchte, ob es funktioniert, fügt einen Debug nun in den Flow ein und verbindet diesen mit dem Ausgang unseres “rpi – keyboard” Nodes. Nach einem Klick auf Deploy oben rechts sollte nun nach jedem druck auf der Fernbedienung auf einen angelernten Knopf, eine Nachricht im Debug Fenster auftauchen. So weit so gut.
Nun wollen wir uns mit der Außenwelt verbinden. Dafür stehen uns unterschiedlichste Möglichkeiten zur Auswahl. So können wir die Ereignisse bereits mit Node-Red Bordmitteln in eine Datei schreiben, mit einem Webservice Aufruf koppeln oder auch eine Nachricht über einen Websocket übertragen. Auch stehen MQTT, TCP, UDP und sogar die serielle Ausgabe als Übertragungsmöglichkeit im Standard offen. Damit sollte eigentlich schon jeder Wunsch abgedeckt sein, aber noch mehr Komfort zur Integration in bestehende Smart Home Netze gibt es durch optionale installierbare Module. So machen wir unser Setup mit dem Modul “node-red-contrib-homekit-bridged” z.B. zu einem HomeKit Endgerät nach Apple Standard. Das gleiche funktioniert auch mit OpenHab https://flows.nodered.org/node/node-red-contrib-openhab3 oder sogar Alexa https://flows.nodered.org/node/node-red-contrib-virtual-smart-home und eigentlich allem was es so auf dem Markt gibt und über ein Netzwerk kommuniziert. Ich persönlich habe mich für die Übertragung via Websockets ohne zusätzliches Modul entschieden.
Halt, Stop! Warum auf einmal jetzt Websockets? In meinem ersten Aufbau hatte ich die Kommandos der Fernbedienung über eine “normale” API zu übertragen versucht. Das funktioniert zwar ebenso prächtig ist aber zu langsam! Beim Drücken eines Knopfes auf einer Fernbedienung erwartet jeder eine sofortige Reaktion bzw. Aktion. 1 Sekunde Verzögerung fühlt sich unnatürlich an, 2 Sekunden sind bereits unerträglich. Man stelle sich vor man will z.B. die Lautstärke des Fernsehers stück für stück erhöhen. Ganz schnell habe ich 20-mal oder öfter gedrückt und die API-Kommandos werden langsam abgearbeitet. So arbeitet man erfolgreich an einem Hörsturz. Jeder der jetzt gerade Kopfkino spielt: Ja, genau so ist es mir ergangen…
Vor ähnlichen Erfahrungen möchte ich euch schützen und deswegen greifen wir gleich auf Websockets zurück. Ohne zu tief in die Grundlagen der Informatik eingehen zu wollen, handelt es sich bei Websockets um eine Interprozesskommunikation (IPC) über das HTTP (WEB) Protokoll. Anders formuliert: Mit Websockets bauen wir einen Tunnel zwischen zwei oder mehr Geräten zur Echtzeitkommunikation auf. Genau was wir hier brauchen!
Der zweite Knoten, den wir in den Flow ziehen ist also ein “Websocket out” aus dem Netzwerkbereich. Auf diesen hört wiederum ein „Websocket in“ in meiner Heimautomatisierungslösung, die ebenfalls mit Node-Red realisiert ist. Wenn ihr ein anderes System zur Heimautomatisierung einsetzt, wäre die Eingabe des “rpi – keyboard” Nodes/Knotens an das entsprechende Modul weiterzuleiten. So lässt sich eben auch, wie in der Einleitung angekündigt, jedes andere Gerät in euer IoT einbinden.
Fazit
In unserem kleinen Versuch haben wir spielerisch aus einer alten Infrarot Fernbedienung eine sinnvolle Erweiterung unserer Smart Homes geschaffen. Da unser Raspi Zero nur wenig Strom verbraucht, wäre theoretisch auch eine Energieversorgung über einen Akku oder eine Powerbank denkbar, womit das ganze Setup sogar mobil werden würde.
Der ein oder andere “Profi” wird darüber geschimpft haben, warum ich auf dem kleinen Raspberry Pi Zero eine Desktopumgebung installiert habe, anstelle darauf der geringen Ressourcen zuliebe zu verzichten. Das habe ich probiert und das Anlernen der Fernbedienung über FLIRC hat auf diese Art reichlich wenig Spaß gemacht. Außerdem sagt uns htop, dass auf dem Raspi auch bei laufendem Desktop nur ca. 100 von 512 MB Arbeitsspeicher belegt sind.
Ich hoffe der Artikel war interessant und hat zu der ein oder anderen neuen Idee für private oder auch berufliche Projekte geführt!
Jeder, der sich mit Internetauftritten beschäftigt, hat sicherlich schon von Google Analytics (https://de.wikipedia.org/wiki/Google_Analytics) gehört. Damit kann man u.a. sehen von wo, unter welchen technischen Bedingungen, wann auf welche Seiten eben dieser zugegriffen wird. Matomo (https://matomo.org/) steht nicht für ein Mozarella-Sandwich mit Mayonaise und Tomaten, sondern ist ein Open Source Tool mit dem sich gleiches und teilweise sogar mehr erreichen lässt. In diesem Artikel gehe ich auf die Vorteile bei der Nutzung von Matomo ein und liefere auch gleich ein Beispiel, wie es sich schnell nutzen lässt.
Datenkrake – aber besucherfreundlich
Der wesentliche Vorteil bei der Nutzung von Matomo besteht darin, dass man es selbst betreiben (https://hub.docker.com/_/matomo) kann, und man so die volle Kontrolle darüber hat welche Daten vom Besucher wo gespeichert werden. Ich selbst nutze das Tool nun schon seit vielen Jahren und habe nur positives darüber zu berichten. Es lässt sich ganz Datenschutzkonform (https://www.it-recht-kanzlei.de/matomo-richtig-verwenden-dsgvo.html) und trotzdem granular einstellen, welche Informationen gespeichert werden. Für aussagekräftige Analysen braucht man z.B. nicht die komplette IP-Addresse des Besuchers zu speichern, um nur eine der vielen Optionen zu nennen. Auch setzen Tools wie Google Analytics stark auf den Einsatz von digitalen Fingerabdrücken (Cookies), dazu gleich mehr. Aber so viel vorab: mit Matomo lässt sich der Einsatz von Cookies auf Wunsch sogar komplett deaktivieren!
Wie installiere und benutze ich den Matomo?
Bei Matomo gibt es grundsätzlich zwei Arten des Betriebs und eine Weitere die dazwischen liegt.
Die Matomo Cloud – so verdient der Anbieter von Matomo, neben zusätzlichen erwerbsfähigen Plugins, sein Geld. Analog zu Google Analytics, vertraue ich die Daten meiner Benutzer einem Drittanbieter an. Irgendwie ja das, was wir genau nicht wollen.
Integriert als Plugin in ein Web Content Management System (WCMS) – Für WordPress und andere gibt es eine komplette Installation von Matomo als Plugin, welches sich über den jeweilig verfügbaren Markplatz hinzufügen lässt. Hier haben wir keine Möglichkeit der Trennung von Webseiten-Content und Analytics. Das ist deshalb auch nicht besonders performant und nur für kleinere Installationen geeignet. Außerdem geht das natürlich nur, wenn man eines der unterstützten WCMS einsetzt.
Selbst Hosten – Das ist was ich hier beschreibe und mittels einem von Matomo selbst vorgefertigtem Container (https://hub.docker.com/_/matomo) auch ganz einfach geht.
Eine “saubere” Möglichkeit Matomo zu installieren ist also über Docker Compose Container. Im Appendix habe ich eine entsprechende Beispieldatei angehangen. Was ich hier abermals unterschlage ist die Konfiguration des Reverse-Proxies samt seiner Konfiguration. Wir gehen einfach davon aus, dass ich für meine Subdomain stats.handtrixxx.com mit dem Nginx Reverse Proxy Manager die benötigten Einstellungen vorgenommen habe und auch von dort aus ein entsprechendes Zertifikat von Let’s Encrypt bekommen habe.
Nachdem das alles eingestellt und hochgefahren ist (Dauer ca. 20 Minuten), können wir uns and der Weboberfläche von Matomo für die initiale Konfiguration anmelden. Wie das funktioniert, ist ausführlich und gut hier https://matomo.org/docs/installation/ beschrieben. Dank Docker Container können wir den ersten Teil der Anleitung komplett überspringen und setzten ungefähr an der Stelle “Super User” an.
Wie binde ich Matomo nun in meine Web-Seite/App ein?
Wie, wenn wir auf https://matomo.org/docs/installation/ ein bisschen gescrollt haben, an gleicher Stelle beschrieben lässt sich nun der Einsatz auf einer ersten Website durchführen. Damit wird auch deutlich, dass mit einer einzelnen Matomo Installationen auch mehrere Websites/Apps getrennt voneinander oder zusammen anbindbar sind.
Zur Einbindung in eine Website lässt sich, wie im Standard vorgeschlagen, entweder ein JavaScript Snippet verwenden oder aber ein “unsichtbares” Bild über den sogenannten Image Tracker einfügen. Auf diese Art lässt sich nun auch einstellen, dass KEIN Cookie beim Anwender zum Tracking genutzt werden soll. Prima!
Wartung
Abschließend ein paar Tipps zur Wartung unserer Installation. Wie ihr, falls ihr selbst eine Installation vorgenommen habt, evtl. schon gesehen habt wird die Verfügbarkeit eines Updates von Matomo direkt in der Web-GUI angezeigt und kann auch von dort aus durchgeführt werden.
Um die Container selbst auch aktuell zu halten, reicht das gelegentliche und auch automatisierbare Ausführen von docker-compose pull , mit anschließendem docker-compose up -d aus dem Stammverzeichnis eurer Docker Compose Umgebung heraus.
Das ist einfach.
Fazit
Definitiv hat das Schreiben dieses Artikels länger gedauert als eine Matomo Installation. Außerdem konnte ich hoffentlich verdeutlichen, dass es im Vergleich zu anderen Web-Analytic Tools mit Matomo keine wesentlichen Einschränkungen, aber jede Menge Vorteile gibt. Ein kleiner Wermutstropfen ist vielleicht, dass sich die Art der Reports in der Web-GUI nicht besonders “verbiegen” lässt. Wahrscheinlich wäre das aber auch nur für größere Unternehmen überhaupt wünschenswert. Außerdem gibt es dafür, vielleicht als abschließender Lichtblick, eine großartige API die es uns erlaubt die über Matomo erfassten Daten in einer Applikation unserer Wahl zu verwenden! Siehe: https://developer.matomo.org/api-reference/reporting-api. Eigentlich war der Artikel nur als “kurze” Ergänzung zu einem Vorherigen (Mehr als nur Performance King – Headless CMS, APIs und IoT für die Website) gedacht, bei dem es u.a. um das Aufsetzen einer Website mit einem Headless CMS ging. Es ist aber nun doch “etwas” länger geworden. Ich bitte die vielen Fachbegriffe zu entschuldigen. Aufgrund des heterogenen Zielpublikums ist die Wortwahl nicht immer ganz einfach.
Appendix
Hier ein Beispiel einer docker-compose.yml zur einfachen Inbetriebnahme von Matomo.
Wie im Artikel “Die (beinahe) perfekte Website – Teil 1: Anforderungen” bereits angerissen, kommen bei Gestaltung und Umsetzung eines modernen Internetauftritts eine Vielzahl von Faktoren zusammen. Für alle denen eine einfache WordPress Installation nicht reicht, oder für die die möglichen Alternativen kennen lernen möchten, stelle ich in diesem Post meine Umsetzung mit Hilfe der Tools Cockpit, Node-RED und weiteren Helferlein vor.
Was ist das Ziel?
Ich wollte erreichen dass meine Seite(n) beim Besucher weit unterhalb von 2 Sekunden geladen werden und dort hübsch und zeitgemäß dargestellt werden. Außerdem wollte ich dazu moderne Techniken und Tools verwenden. Soviel vorab: das Meiste davon ist mir gelungen :-). Bei der Auswahl der Tools habe ich größtenteils mir vertraute Lösungen genommen, mit dem headless CMS Cockpit aber auch etwas Neues ausprobiert. Aber der Reihe nach.
Es ist beinahe lustig dass das 2021 (wieder) der Fall ist, aber Microsoft Visual Studio Code(VS Code) ist tatsächlich beinahe das Wichtigste dieser Werkzeuge. Back to the Roots und ein klares Nein an die Generatoren von chaotischem und langsamem Quellcode wie WordPress, Jimdo usw. es nun mal sind. Außerdem ist VS Code weit mehr als nur ein erweiterter Text-Editor, sondern auch Open Source Tool zur Administration ganzer Containerlandschaften und natürlich vorzüglich zum Debugging. Vor einer Weile hatte ich dazu auch folgendes Anwendungsbeispiel geschrieben: Quellcode auf GitHub verwalten mit Visual Studio Code
Seit Veröffentlichung von Version 5 des Open Source Frontend Toolkits Bootstrap von Twitter, ist dieses schneller den je zuvor. Man hat sich endlich des unnötigen Overheads des jQuery Frameworks entledigt und setzt nun vollständig auf natives “Vanilla” Javascript. Das gleiche habe ich bei den wenigen selbst geschriebenen Funktionen im Frontend natürlich auch gemacht. Bootstrap selbst stellt CSS Klassen, Icons, Komponenten und vieles mehr zur Verfügung, die bei der Entwicklung von UI/UX unwahrscheinlich viel Zeit und Aufwand sparen.
Mit den Open Source Web Content Management System (WCMS) Cockpit von Agentejo, gelingt die saubere Trennung von Back- und Frontend. Neben den für ein CMS üblichen Funktionalitäten zur Pflege- und Verwaltung von Web-Content und einer Medienverwaltung macht die integrierte API den Unterschied. Dazu später etwas mehr.
Das ursprünglich von IBM initiierte Open Source Projekt Node-RED ist vielleicht die zur Zeit beste Implementierung einer Internet of Things (IoT) Low-Code Platform. Sowohl die Einschränkung “Low-Code” als auch auf IoT, werden dem Tool aber nicht ganz gerecht. Zwar ist es mal für diese Szenarien entwickelt worden, lässt sich aber ohne Mühen auch für ganz viel Code und zur Abbildung aller möglichen vorstellbaren Prozesse nutzen. Ein Beispiel folgt.
Einige weitere benötigte Werkzeuge und Helfer wir den Nginx Reverse Proxy Manager, Let’s Encrypt SSL Zetifikate, Matomo Analytics, Docker(-Compose) und weitere würden hier vom Fokus ablenken, weshalb ich sie erstmal außen vor lasse.
Warum?
Die Frage zum warum ist einfach zu beantworten; vor allem beruflich setze ich mich täglich mit den Hürden und Schwierigkeiten beim Umgang mit monolithischen Systemen auseinander. Andererseits propagieren Unternehmen wie die SAP neue Headless Ansätze. Das und meine innere Neugier haben mich angetrieben, einfach für mich selbst solch ein Setup vorzunehmen um evtl. neue Risiken, aber vor allem Möglichkeiten kennen zu lernen. Oder in kurz: Weil ich es können will und es gar nicht so schwierig ist.
Wie genau?
Die Installation von Cockpit CMS und Node-RED in eigenständigen Containern geht schnell von der Hand und sollte in maximal 20 Minuten erledigt sein. Im Appendix, als Hilfestellung, meine Docker-Compose Dateien.
Jetzt geht es ans “Eingemachte”. Nach dem Entwurf des Layouts und der Umsetzung des Prototypen mit Bootstrap, lagere ich sämtlichen statischen HTML Content nach Cockpit CMS in Form von dort sogenannten “Singletons” aus. Die haben den Vorteil, dass sie mit Attributen wie Sprache und Version, etc. versehen werden können. Theoretisch könnte man das auch mit den CSS und Javascript Dateien machen, aber die bearbeite ich dann doch irgendwie lieber in Visual Studio Code. Als nächstes erstellen wir nun eine sogenannte “Collection” in Cockpit, die sozusagen den Rahmen um unsere Posts bildet. So ließe sich z.B. mit einer Cockpit Installation der Content für viele Websites verwalten. Klasse! Bilder, Grafiken und der Gleichen lassen sich auch mit Cockpit komfortabel verwalten und vor allem von dort aus auch automatisch als Thumbnails umwandeln. Noch besser! Der Zugriff auf das Ganze erfolgt dann über Web APIs, auf die ich gleich weiter eingehe. Und noch etwas; über sogenannte Webhooks lassen sich auch genau andersherum von Cockpit aus Aktionen starten. So starte ich z.B. bei jedem speichern/ändern der Collection automatisch ein Deployment der kompletten Website. Wow! Eigentlich war Cockpit einfach nur mein erster Google Treffer bei der Suche nach einem Headless CMS, aber mir fällt gerade kein Grund mehr ein warum ich wechseln bzw. mir andere ansehen sollte.
Und nun kommt Node-RED ins spiel, denn ich muss meine Inhalte ja nun irgendwie unter unter niklas-stephan.de verfügbar machen. Eigentlich geht es mir darum, mit dem Ziel maximaler Performanz, statische Seiten zu generieren. Bei einer Google Suche nach “Static Site Generators” ist Node-RED garantiert nicht auf der ersten Seite der Suchergebnisse zu finden. Dafür gibt es unzählige andere Tools, die aber auch wieder eine Einarbeitung und meistens auch das Erlernen einer eigenen Syntax erfordern. Durch meine umtriebigen Aktivitäten im Umfeld der Heimautomatisierung, ist mir aber nun Node-RED bestens vertraut und eigentlich will ich doch nur einen relativ einfachen Prozess abbilden. Und der sieht wie folgt aus:
Start des Deplyoments manuell oder durch Webhook
Sammeln aller statischen Quellen
Sammeln aller vorhanden Singletons und Posts
Dynamische Generierung von Meta-Daten
Rendern der einzelnen Seiten
Speichern der Seiten auf Platte und im Arbeitsspeicher
Wer sich die Mühe machen möchte mal kurz im Console Log dieser Seite zu gucken sieht, dass ich bei jedem Deployment Zeitpunkt und Dauer protokollieren lasse. Da sehen wir dann auch dass der beschriebene Prozess insgesamt 0,099 Sekunden dauert. Und das auf einem Server der nebenbei u.a. noch Monero schürft und meine Cloud Umgebung bereit stellt. Also eigentlich schon recht fix, aber um noch “eins Drauf” zu setzen lege ich die erzeugten Dateien im letzten Schritt im “/dev/shm”, sprich dem Arbeitsspeicher des Servers ab, von wo aus sie der Reverse Proxy beim Zugriff zur Verfügung stellt. Da braucht’s vorerst kein CDN mehr und mein Ziel ist erreicht. 🙂
Willkommen zum ersten, wirklich langen Beitrag meiner Website, in dem ich darauf eingehe, was alles erforderlich ist um einen Internetauftritt besonders gut zu gestalten. Um zu beweisen, dass die gestellten Anforderungen auch erfüllt werden können, nutzen wir meine Domain niklas-stephan.de um das Gelernte, soweit möglich, auch gleich direkt umzusetzen.
Was ist schon perfekt und wer definiert das? Im Falle eines Internetauftritts ist diese Frage vielleicht einfacher zu beantworten als in anderen Fällen. Denn, egal wie gut Gestaltung und Umsetzung gelungen sind, muss die Seite erst einmal von einem Besucher gefunden werden. Mit einem Markanteil von über 90% (https://blog.hubspot.de/marketing/google-trends-suche) ist da die Google Suchmaschine eigentlich der einzige ausschlaggebende Faktor. Als Schlussfolgerung kann mann also sagen, dass die Optimierung einer Website auf von Google definierte Faktoren gleichzeitig nah an eine perfekte Website führt. Welche Faktoren das sind und welche Weiteren noch eine wichtige Rolle spielen, sehen wir uns nun im ersten Teil unserer Artikelserie an.
Aus Sicht des Besuchers
Faktoren zur Bewertung Neben viel Literatur und Informationen gibt Google mit dem Werkzeug “Lighthouse”, welches in jede Installation des Browsers Chrome integriert ist, einen Einblick auf die Kriterien die sie an eine Website Stellen. Diese sind:
Es taucht noch ein weiter Punkt “Progressive Web App” (PWA) in Lighthouse auf. Um aus HTML5 eine echte WebApp zu machen müssen nämlich eine Menge von Anforderungen erfüllt werden. Dazu später mehr in einem anderen Beitrag zu meiner App zur Hausautomatisierung. Für eine Website im eigentlichen Sinn ist der Punkt PWA jedenfalls irrelevant. Der Screenshot hier zeigt eine Lighthouse Bewertung einer im Internet tausendfach frequentierten Seite, die aber offensichtlich nicht die gestellten Kriterien zu Googles voller Zufriedenheit erfüllt. Dies ist durchaus üblich bzw. nicht ungewöhnlich, denn noch viele weitere Faktoren entscheiden über den Erfolg eines Internetauftritts.
Wen es interessiert wie diese Bewertung zustande kommt, der kann wie gesagt über die Entwicklertools von Google Chrome (Öffnen sich mit Taste F12) im Tab “Lighthouse” eine beliebige Seite bewerten lassen und sich das Ergebnis ansehen. Praktischerweise gibt Lighthouse auch gleich noch Tipps dazu aus, wie sich die Punktzahl weiter erhöhen bzw. die Seite optimieren lässt.
Deshalb orientieren wir uns in den nächsten Kapiteln genau an diesen Faktoren.
Performance
Seit dem die Übertragungsgeschwindigkeit der Endgeräte des Webseitenbesuchers nicht mehr der limitierende Faktor sind, müssen sich Webseiten mindestens genauso “schnell” anfühlen wie eine Applikation die auf unserem Endgerät fest installiert ist. Google gibt in seinem Playbook so den dringlichen Rat dazu, dass eine Seite innerhalb von 2 Sekunden geladen sein muss um die Benutzererfahrung nicht zu schmälern. Um unter diesen 2 Sekunden zu bleiben kann man sich vieler Stellschrauben bedienen:
Starke Infrastruktur / Hardware mit einer guten Netzwerkanbindung
Ein möglichst geringes Datenvolumen einer Seite
Kompression von Dateien und während der Datenübertraung
Reverse-Proxy Konfiguration und Caching
Content Delivery Networks (CDN) für lokales Caching
Kein/wenig Server-Side Rendering
“Sauberer” und sparsamer Quellcode
Auf das (nach)laden, besonders von externen Inhalten, sollte möglichst verzichtet werden
Jeder der aufgelisteten Punkte ist mindestens ein eigenes Kapitel Wert und wir werden in unsere Kapitelserie dementsprechend darauf eingehen.
Accessibility
Egal wie schnell sich die von uns aufgesuchte Seite auch aufgebaut hat, wenn der Autor meinte es sei eine gute Idee alles in einer Schriftgröße von 5 Pixeln in hellgrauer Schrift unter Verwendung eines Comic Sans Fonts auf weißem Hintergrund anzuzeigen, ist der Spaß vorbei. Auch Laufschriften mit Telefonnummern zum Abschreiben und großzügige Nutzung von Neon-Farben sind Effekte die in einem höchstens die Gewaltbereitschaft steigern. Vielleicht nicht ganz so übertrieben aber ähnlich hat sicherlich jeder von uns schon einmal Erfahrungen im Internet gemacht. Um solchen Situationen entgegenzuwirken achtet man als Webseitenbetreiber, neben der generellen User Experience (UX – Berufserfahrung), auch auf die Accessibility, sprich die Erreichbarkeit / Zugriffsfähigkeit seiner Inhalte. Dabei gilt es zu bedenken:
Nicht jeder Mensch kann gut sehen
Manche Menschen können überhaupt nicht sehen und lassen sich die Inhalte von einer Maschine vorlesen Menschen nutzen unterschiedliche Endgeräte mit unterschiedlichen Auflösungen Auf die Verwendung evtl. verwirrender Effekte sollte man möglichst verzichten, wenn sie nicht ein Kernelement der Seite darstellen. Die Seitenstruktur sollte klar und hierarchisch sein, z.B. nicht am Anfang der Seite mit einer h4 Überschrift anfangen und dann mitten im Text h2 verwenden. Es sollten möglichst keine oder zumindest nur wenige Maßnahmen getroffen werden, die den Nutzer daran hindern die Darstellung seinen Bedürfnissen nach anzupassen. Wenn mann sich daran hält, wird man auf modernen Endgeräten/Browsern automatisch durch die Bereitstellung seiner Seite mit der “Reader” Option belohnt, die ein eBook-artiges lesen der Artikel ermöglicht.
Best Practices
Es gibt eine Reihe von empfohlenen Maßnahmen um die korrekte Darstellung der Seite beim Besucher zu Gewährleisten und um bestimmte Sicherheitsstandards einzuhalten. Außerdem prüft Lighthouse hier noch, dass die Seite keine offensichtlichen Fehler in der Programmierung enthält und gängige sowie akutelle Standardtechniken umgesetzt wurden. Insgesamt werden bis zu 17 Kriterien geprüft, von denen ich hier die wichtigsten Aufliste.
Verwendung von https zur Verschlüsselung der Datenübertragung zwischen Nutzer und Betreiber. Schon vor 2021 eigentlich ein absolutes Muss.
Verzicht auf nicht unbedingt erforderliche JavaScript Features
Keine JavaScript Fehler auf der Seite. Korrekte Formatierung des HTML Codes bezüglich wesentlicher Merkmale wie z.B. der eingesetzten Sprache. Das klingt eigentlich nach nicht viel und leicht umzusetzen. Wer sich aber einmal die Mühe macht sich die Fehlerprotokolle durchzulesen die von einer großen Anzahl gängiger Websites “ausgespuckt” werden, staunt nicht schlecht. Offenbar ist es selbst großen Unternehmen nur schwer möglich, ihre Entwickler dahingehend zu motivieren, dass solche Fehler ausgeschlossen sind. Zur Verteidigung der Entwickler aber vor allem deren Motivation, muss man allerdings sagen dass verschiedene Browser gerade mit JavaScript verschieden umgehen und manchmal Kompromisse geschlossen werden müssen.
SEO
Wie schon zu Beginn des Artikels erläutert, bringt uns die schönste Website nichts, wenn sie niemand findet. Falls wir dann auch noch nicht gewillt sind tief in unsere Taschen zu greifen, um Werbekampagnen zu finanzieren, dann aber eigentlich auch immer müssen wir uns mit Search Engine Optimization (SEO) beschäftigen. Früher bestand die Optimierung für Suchmaschinen zum großen Teil darin, brav ein paar Schlüsselwörter (Keywords) in die Meta Informationen unseres Auftritts einzubauen. Das reicht heute bei weitem nicht mehr aus und die vergebenen Keywords werden sogar in der Regel von den gängigen Suchmaschinen gar nicht mehr beachtet. Dafür sind nun eine Vielzahl anderer Faktoren entscheidend dafür ob wir (gut) gefunden werden oder nicht. Einige der wichtigsten davon sind hier aufgelistet:
Die Seite enthält Metainformationen, wie: Beschreibung, Titel, Bild, Link, usw.
Die Seite hat einen längeren wirklichen Inhalt in Textform
Möglichst alle Links auf der Seite haben eine Beschreibung (Text)
Alle Bilder auf der Seite haben eine Bezeichnung (alt)
die Seite ist z.B. über eine robots.txt Datei so eingestellt, dass sie von Suchmaschinen indiziert werden darf
die robots.txt enthält, wenn vorhanden, keine Fehler
Es werden keine “Mini” Schriftgrößen verwendet um Inhalte vorzutäuschen (eine Zwischenzeitlich verbreitete Masche unseriöser Anbieter)
Die Seite / Der Beitrag enthält interne und externe Links zu anderen Seiten
Wie man sieht zielen diese Kriterien darauf ab, dass neben den Metainformationen die auch für Soziale Netzwerke relevant sind, der komplette Seiteninhalt bei der Indizierung der Seite durch Suchmaschinen berücksichtigt wird. Das ist auch ein weiteres Argument, neben der Performance, Inhalte nicht dynamisch nachzuladen, weil eben diese dann von Google&Co nicht gefunden werden.
Social Media
Aus Sicht eines Unternehmens heute beinahe überlebensnotwendig, aus Sicht einer Privatperson einfach eine hilfreiche Unterstützung um Inhalte bekannt zu machen und mit der Welt zu teilen, das ist Social Media Integration für eine Website. Die schon zuvor genannten Meta-Informationen ermöglichen es, dass beim Teilen eines Links automatisch ein Bild, eine Überschrift und eine Kurzbeschreibung generiert werden. Außerdem ermutigen Schaltflächen mit den Symbolen der verschiedenen Netzwerke in der Nähe eines Beitrags zum Teilen. Man kann auch berücksichtigen, dass je nach Endgerät unterschiedliche Kanäle genutzt werden. So macht ein Share Button zu WhatsApp in der Regel nur für mobile Endgeräte Sinn. Auch werden von unterschiedlichen Altersgruppen unterschiedliche Netzwerke bevorzugt. Dabei kann man sich hieran orientieren:
Facebook: Wird primär von Menschen mittleren bis höheren Alters genutzt, ist aber wohl jedem als Pionier bekannt. Instagram: Junge Erwachsene bis Menschen mittleren Alters nutzen dieses Netzwerk hauptsächlich zum Teilen von Bildern und Geschichten dazu. TikTok: Für die ganz jungen Mitmenschen. Da wird wohl hauptsächlich getanzt, geklatscht und dazu gesungen, um das Ganze dann auch noch als Video zu teilen. Twitter: zum Austausch von Kurznachrichten und so richtig im sogenannten Arabischen Frühling weltweit bekannt geworden. Bis vor kurzem auch Stammsitz einer orangen Ente. Zielpublikum sind inzwischen eher Menschen mittleren bis höheren Alters. YouTube: Mit etwas Aufwand auch als Soziales Netzwerk nutzbar, wird dafür aber altersgruppenübergreifend genutzt WhatsApp: eher zum persönlichen Austausch in kleineren Zielgruppen, dafür aber ebenfalls altersgruppenübergreifend. Natürlich gibt es auch regionale Unterschiede bei der Nutzung der Netzwerke, so sieht in China oder Indien das Bild schon wieder ganz anders aus. Z.B. tritt dort der Anbieter WeChat mit seiner App als eierlegende Wollmilchsau auf.
Browser Kompatibilität
Hier muss man eine Entscheidung treffen. Leider nutzen nach wie vor viele Menschen den völlig veralteten Internetbrowser “Internet Explorer” (IE11) von Microsoft. Dieser wird schon seit längerem nicht mehr von Microsoft weiterentwickelt und wurde durch “Edge” ersetzt. Da nun aber viele trotzdem noch den IE11 nutzen, ist die zu treffende Entscheidung: Will ich diese Besucher ebenfalls mit einer fehlerfreien Darstellung bedienen oder schließe ich sie aus, damit ich mich bei der Erstellung der Seite an aktuelle Standards halten kann und diverse Altlasten nicht berücksichtigen muss. Ich habe mich gegen die Unterstützung des IE11 entschieden, da selbst Microsoft nach Supportende von Windows 7, an welches der IE11 gekoppelt ist, diesen als Sicherheitsrisiko einzustufen plant. Die anderen üblichen Browser wie Google Chrome, Chromium und Microsoft Edge oder auch Apple Safari liefern stets gute Ergebnisse. Das Open Source Projekt Firefox der Mozilla Gruppe ist die Wahl des Nutzers mit Wunsch nach Unabhängigkeit. Auch Firefox stellt die meisten Inhalte des aktuellen HTML Standards korrekt dar und unterstützt nur z.B. einige exotischere Parameter in CSS nicht.
User Experience und Layout
Für ein Unternehmen sicherlich nicht nur ein Unterpunkt für mich als Privatperson mehr eine Hilfe. Unter User Experience (UX) wird die komplette Berufserfahrung die der Besucher während des Besuchs unserer Website macht zusammengefasst. Dazu gehört das Layout oder auch User Interface (UI) unserer Seite als Kernelement. Sich wiederholende Elemente sollten auf allen (Unter)Seiten gleich aussehen und generell sollte während des kompletten Besuchs eine Wiedererkennungswert geschaffen werden. So sind Buttons immer an der gleichen Stelle zu finden, verhalten sich identisch und sehen gleich aus. Auch das Farbschema sowie die komplette Formatierung der Inhalte sollten durchgängig und ansprechend sein. Ich vertraue hierzu als Einstieg schon seit einigen Jahren auf das Open Source Projekt “Bootstrap” (Link) von Twitter. Dieses beinhaltet im wesentlichen vorgefertigte CCS (Styles) die nach belieben verwendet werden und ggfs. auch angepasst werden können. Bootstrap hatte zwischenzeitlich etwas an seinem guten Ruf eingebüßt, weil es lange auf das JavaScript Framework “jQuery” gesetzt hat. Mit der aktuellen Version 5 ist das Geschichte und wir freuen uns über einen kleineren Quellcode bei der Einbindung.
Aus Sicht des Betreibers
In den vorherigen Kapiteln haben wir herausgefunden, was aus Sicht von Google bei der Ausspielung einer Website relevant ist. Natürlich haben wir aber neben den Anforderungen aus Besuchersicht auch noch sowohl als Autor als auch als Administrator weitere Anforderungen. Einige davon werde ich hier anführen, andere später in der Artikelserie auch noch tiefgreifender ausführen.
Server
Wie zuvor im Punkt Performance schon beschrieben ist ein schneller Server mit einer sehr guten Netzwerkanbindung ans Internet eines der Kernkriterien für eine performante Website. Anbieter für virtuelle oder physische Server gibt es viele. Einige der Bekanntesten sind Hetzner, 1blu, Netcup oder Strato. Man hat also die Qual der Wahl. Heute immer mehr üblich ist anstelle des Betriebs eines eigenen Servers, die Nutzung von Ressourcen eines Cloud Anbieters. Hier Stellen Google, Amazon und Microsoft die Platzhirsche dar. Aus Sicht des Datenschutzes stellen alle drei Anbieter mittlerweile auch Ressourcen aus Deutschland bereit und halten sich dementsprechend an die hier gültigen Regulierungen. Ich persönlich bin aber aufgrund der variablen Abrechnung kein Fan der Cloud Anbieter und bezahle lieber einen monatlichen fixen Betrag der sämtlichen Traffic sowie die Hardwarekosten beinhaltet.
Monitoring & Alerting
Das Monitoring, also die Überwachung des Serves ist nicht nur in Problemfällen wichtig, sondern hilft auch dabei Problemen bereits entgegen zur wirken bevor sie auftreten. Ich nutze zum Monitoring das mit dem CentOS Betriebsystem ausgelieferte Open Source Tool Cockpit, welches eine schicke Weboberfläche für die meisten anliegen liefert. So lassen sich dort automatische Updates und eine Langzeit-Ressourcenüberwachung inkl. Dashboard mit ein paar Mausklicks aktivieren.
Viele setzen ein Alerting, also die Alarmierung im Fehlerfall, mit einem Monitoring gleich. Das ist so nicht ganz korrekt. Ein Alerting kann durchaus völlig unabhängig vom Monitoring konfiguriert und genutzt werden. So nutze ich z.B. nur Alerts die mir eine E-Mail senden wenn meine Website keinen gültigen Inhalt zurück liefert. Wem das reicht, der braucht keine schwergewichtige Softwarelösung zu installieren. Wichtig ist nur: Die Überwachung sollte auf keinen Fall auf dem gleichen Serversystem wie unsere Website laufen. Der Grund ist klar: Wenn der Server ausfällt kann er mir auch keine E-Mails mit der Info über den Ausfall liefern… Deshalb kommen meine Mails von einem kleinen Raspberry PI der zuhause auch schon vorher seinen 24-Stunden Dienst verrichtet hat. Und im Normalfall kommen eigentlich auch gar keine Mails, weil der Server einfach nicht ausfällt 🙂
Datensicherung
Das eine Datensicherung zwingend erforderlich ist, braucht man heute glücklicherweise niemanden mehr zu erklären. Ich nutze für die Website genauso wie vor andere Komponenten auf meinem Server eine mehrschichtige Backupstrategie: Eine tägliche Spiegelung der Inhalte innerhalb der Servers lässt mich versehentlich gelöschte Inhalte sehr schnell wiederherstellen. Diese Spiegelung ist dann auch die Quelle um die Daten inkrementell abgesichert an den zuvor erwähnten Raspberry Pi zuhause zu übertragen. Genau genommen an ein dahinter liegendes Hardware RAID Plattensystem. So habe ich zumindest alles mir mögliche getan um sowohl das versehentliche Löschen, einen Datenverlust oder einem Datenträgerausfall entgegen zu wirken.
Domain und DNS
Die Adresse(n) unter denen wir im Internet erreichbar sein wollen werden als Domains bezeichnet. Diese sichert man sich für geringes Geld bei einer Vielzahl von Anbietern, wenn man einen kreativen und nicht bereits belegten Namen gefunden hat. Und genau da liegt die Schwierigkeit, die meisten “hübschen” Namen sind bereits vergeben und man muss wirklich kreativ werden. Eine Nacht darüber zu schlafen bevor man die Registrierung anstößt kann wirklich helfen.
Der DNS Eintrag ist das Bindeglied im Internet zwischen unseren registrierten Domains und der IP-Adresse unseres Servers. Oft übernehmen Anbieter von Domains auch gleichzeitig die Registrierung und Verteilung des DNS Eintrags für genauso geringes Geld.
Sicherheit
Neben dem eigentlich schon verpflichtenden Einsatz von Verschlüsselung über https://, welche auf meinem Server über das Open Source Tool “Nginx Proxy Manager” (Link) einrichte, kann man noch mehr für die Sicherheit von Besuchern und uns als Betreibern tun. Ein großer Mehrwert zur Sicherheit ist während der Umsetzung als Nebenprodukt entstanden. Da ich ausschließlich statische Seiten generiere und auf den Einsatz von Cookies verzichte, beschränkt sich der Besucher dieser Seiten fast vollständig auf den bloßen Download von Dateien ohne Nachladen weiterer Inhalte. Eine Ausnahme spielen die Assets (Bilder, Dokumente, etc.), aber dazu später mehr.
Außerdem sollte natürlich der Zugang zum Server gesichert werden. So ist eine Firewall zu aktivieren und Standardports z.B. für SSH sind zu vermeiden. Auch empfiehlt es sich z.B. mit dem Open Source Tool Google Authenticator eine 2-Faktor Anmeldung am Server zu erzwingen. Eine Verschlüsselung der Daten auf dem Datenträgern des Servers ist, wenn möglich, sicherlich auch keine schlechte Idee. Für den Root user deaktivieren wir noch die Möglichkeit sich aus der Ferne anzumelden und führen selbst unsere Kommandos niemals direkt als dieser aus.
Content Mangagment System
Eine immer populärer werdende Praxis ist der Einsatz eines sogenannten Headless Content Management Systems (CMS) zur Datenhaltung, Verwaltung und ggfs. zum editieren von Beitragen wie diesem hier. Headless bedeutet dass das CMS die in ihm gepflegten Daten nicht direkt sondern nur über Webschnittstellen bereit stellt. Das hat, neben den Vorteilen der Modularisierung und Unabhängigkeit, den Vorzug dass wir unsere Inhalte zur Generierung von statischen Seiten an jedem Punkt unserer Prozesses abfragen können ohne dabei auf Limitierungen des CMS selbst gefesselt zu sein. Ich nutze hierfür das Open Source Tool “Cockpit” (Link), und bin nach einer kurzen Einarbeitungszeit von vielleicht 6 Stunden hellauf begeistert. Das einzig verwirrende ist der Name. Wir erinnern uns: Unser Monitoring Tool heisst ebenfalls Cockpit. Die beiden haben so rein gar nichts miteinander zu tun, sondern teilen sich einfach den Namen.
Asset Management
Im Falle unserer Website sind unsere Assets vornehmlich Bilder. Und diese möchten wir gerne, ähnlich wie unsere Inhalte, autark gespeichert und verwaltet wissen. Außerdem soll unser Asset Management System dazu in der Lage sein, aus den von uns hochgeladenen Bildern automatisch Miniaturen (Thumbnails) zu erstellen. Glücklicherweise kann unser CMS System “Cockpit” (Link) das alles von Haus aus und bietet für den Zugriff auch noch Web Services, mit deren Verwertung wir bereits bekannt sind. In Cockpit ist das Asset Management ein vom CMS getrennter Bereich der aber von dort aus auch angesprochen werden kann, so dass wir Bilder beim Schreiben eines Artikels direkt hochladen und einfügen können.
Backend
Oft habe ich in diesem Artikel über die Generierung von statischen Seiten gesprochen. Aber womit machen wir das eigentlich? Hier bin ich einen unüblichen Weg gegangen, und verwende das Open Source Tool Node-RED (Link). Node-RED ist eine sogenannte Low-Code Programmierumgebung auf die über den Browser zugegriffen wird. Low-Code heisst das man Abläufe von einfacher bis mittlerer Komplexität ohne eigentliche Programmierung abbilden kann. Allerdings lassen sich auch jederzeit eigene Funktionen einbinden, wovon ich auch häufig gebrauch machen. Verschiedene Prozessschritte lassen sich grafisch miteinander verbinden, so dass als Nebenprodukt gleich noch ein Ablaufdiagramm entsteht. Ich nutze das Tool schon seit mehren Jahren z.B. zur Heimautomatisierung, was die Vielseitigkeit widerspiegelt. Es gibt aber auch noch eine Vielzahl anderer Tools die auf die Generierung von statischen Websites spezialisiert sind.
Reporting & Web Analytics
Wenn man so viel Arbeit in die Erstellung von Inhalten und Struktur steckt, möchte man natürlich auch wissen ob und wie diese bei den Besuchern ankommen. Auch wie viele Besucher es überhaupt in welchem Zeitraum gibt und ob sie längere Zeit auf unseren Seiten bleiben interessiert uns. Wenn unsere Inhalte außerdem in mehreren Sprachen oder zumindest auch in Englisch oder Spanisch angeboten werden, dann möchten wir auch wissen woher die Besucher kommen. Um all diese Fragen zu beantworten gibt es sogenannte Web Analytics Tool. Solch ein Tool bereitet die Antworten auf diese Fragestellungen in der Regel auch gleich noch grafisch auf. Das bekannteste unter ihnen ist sicherlich Google Analytics, welches sich kostenfrei in eine Website einbinden lässt. Allerdings ist Google Analytics aus Gesichtspunkten des Datenschutzes nicht besonders sparsam und lässt sich auch nicht selbst betreiben, sondern greift auf die Google Cloud Services zurück. Als Freund des Datenschützers hat sich hingegen das Open Source Tool “Matomo” (Link) erwiesen. Außerdem lässt es sich selbst betreiben, ist flink und geht auf alle genannten Bedürfnisse ein. In Matomo lässt sich auch einstellen, dass Daten nur anonymisiert erhoben werden und z.B. keine IP-Adressen der Besucher gespeichert werden.
Datenschutz & Rechtliche Bestimmungen
Wo wir schon das Thema Datenschutz angesprochen haben, ohne darauf gegenüber dem Webseitenbenutzer einzugehen geht es in Deutschland bzw. der EU nicht. Das ich mich gegen den Einsatz jeglicher Art von Cookies entscheide, vereinfacht diesen Teil aber ungemein (Stichwort: Cookie-Madness). So muss auf der gesamten Webseite aber trotzdem ein stets und einfach auffindbarer Bereich/Link zu den Datenschutzbestimmungen verfügbar gemacht werden. Das gute ist aber: Datenschützer sind keine Unmenschen, im Gegenteil sogar. Sie wollen uns nur vor unlauteren Geschäftspraktiken der Betreiber schützen und sind gegen lange komplizierte “Paragraphenauflisterei”. Das heisst, dass die Datenschutzbestimmungen möglichst kurz und verständlich formuliert sein sollen. Sie sollten außerdem keine Abschnitte enthalten die für die Website gar nicht relevant sind und im Wesentlichen folgendes enthalten:
Welche persönlichen Daten werden gespeichert?
Wo werden die Daten gespeichert?
Von wem werden die Daten gespeichert?
Wer ist Verantwortlicher Ansprechpartner?
Wer darf die Daten auswerten?
Welche Drittparteien sind evtl. involviert?
Wie kann eine Löschung meiner evtl. vom Betreiber gespeicherten Daten initiiert werden?
Wie gesagt müssen aus der Liste nicht alle Punkte relevant sein, z.B. wenn überhaupt keine personalisierten Daten gespeichert werden. Das heisst dass vorgefertigte Texte nicht unbedingt gut sind und vor allem meistens Passagen enthalten die gekürzt/entfernt werden sollten. Natürlich bin ich kein Anwalt und die rechtlichen Grundlagen ändern sich zur Zeit quartalsweise, aber wenn man sich an diese Grundlagen zum Datenschutz hält ist man auf jeden Fall gute dabei und handelt bedachter als viele andere Webseitenbetreiber.
Aus rechtlicher Sicht muss ebenso immer eine Impressum verfügbar sein. Hier kann man sich durchaus an Vorlagen aus dem Internet bedienen, da es sich im Gegensatz zur Datenschutzerklärung hier eher um unsere Absicherung gegenüber dem Nutzer und keine Dienstleistung für ihn handelt. Pflichtangaben sind:
Verantwortlicher für das Angebot gemäß § 5 TMG / § 18 MStV
Beide Angaben sollten den vollständigen Namen, ein Adresse und zumindest eine E-Mail Anschrift enthalten. Hier zählen leider keine Argumente aus Sicht des Datenschutzes für den Betreiber…
Fazit und Ausblick
Wir kennen nun viele Kriterien die eine perfekte Website ausmachen und können bereits sagen, dass sich diese so mit einem Homepagebaukasten oder einem Web Content Managementsystem wie z.B. WordPress nicht umsetzen lassen. In den Folgeartikeln meiner Serie werden wir allerdings auch sehen, dass zur Umsetzung teilweise tiefgreifendes IT-Verständnis benötigt wird. Deshalb Rate ich allen die sich nicht so tief mit dieser Materie auseinander setzen möchten trotzdem zum Einsatz von WordPress. Bei WordPress handelt es sich um ein millionenfach eingesetztes WCMS mit dem man schnell zu passablen Ergebnissen kommen kann und der Umsetzungsaufwand sich auch von Laien bewältigen lässt.
Zusammengefasst ist folgender Anforderungskatalog:
Hosting (Bereitstellung) auf einem flinken Server als Basis
Eine performante Netzwerkanbindung dieses Servers an das Internet
DNS Einträge unser Domain(s)beim einem vertrauenswürdigem Anbieter
Virtualisierung einzelner Komponenten in sogenannten Containern
Server Monitoring mit Cockpit (nicht das CMS Tool)
Alerting mit einer geeigneten schlanken Lösung
Eine Reverse Proxy Konfiguration inkl. Zertifikatsmanagement mit NGINX Proxy Manager
Ein Backend auf Basis von Node-Red zur Generierung statischer Seiten
Content und Asset Management mit Cockpit (nicht das Monitoring Tool)
Web Analytics mit Matomo
Einen Texteditor und Zugriff auf eine Shell mit Microsoft Visual Studio Code
HTML5 Quellcode mit Unterstützung von Twitter Bootstrap 5 (also ohne jQuery) Komponenten
Individuelle Stylesheets mit CSS Variablen
Vanilla (keine Framework wie jQuery oder Angular) Javascript im Frontend
In dieser Reihenfolge werde ich die Themen in den folgenden Artikeln auch beschreiben.
Um noch etwas Spannung aufzubauen: Eine Lighthouse Berwertung von 100% Punkten in allen Bereichen lässt sich umsetzen, diese Seite hier ist der Beweis :-).
Visual Studio Code ist sicherlich einer der besten Texteditoren und inzwischen auch für so ziemlich jedes Betriebssystem verfügbar. Das Tool kann aber weitaus mehr als nur das. Z.B. hat es eine Quellcodeverwaltung über GIT integriert. Das klingt erstmal alles ziemlich trocken, GIT und GitHub haben aber in den vergangenen Jahren zu einer kleinen Revolution im technischen Umfeld geführt und Firmen wie Microsoft oder SAP dazu gezwungen umzudenken. Nun aber der Reihe nach.
Was ist GIT?
Wikipedia sagt dazu: “Git [ɡɪt] ist eine freie Software zur verteilten Versionsverwaltung von Dateien, die durch Linus Torvalds initiiert wurde.” So eine Versionsverwaltung ist aus vielerlei Hinsicht mehr als nützlich. Einige der Hauptgründe dafür sind:
Eine Art von Backup um fehlerhafte Änderungen Schrittweise rückgängig machen zu können und um vor lokalem Datenverlust zu schützen. Viele Menschen können gemeinsam am gleichen Code arbeiten und diesen, wenn gewünscht, auch miteinander teilen. Software Salat: Man kann einen exisitierenden Quellcode kopieren (fork) und darauf afbauend einen neues Projekt starten. Dokumentation (oha!): im automatisch generierten Versionslog ist sichtbar was, wann, von wem geändert wurde. … Mehr dazu: https://de.wikipedia.org/wiki/Git
Was ist GitHub?
GitHub ist eine über das Internet erreichbare Platform, welche es Privatpersonen und Unternehmen ermöglicht GIT ohne eigene Infrastruktur dafür zu nutzen. Außerdem hat sich GitHub innerhalb kurzer Zeit als Quasi-Standard-Standort für Open Source Projekte etabliert. Der Dienst ist so erfolgreich, dass Microsoft sich diesen vor einer Weile einverleibt hat. Das ist erstmal nicht so schlimm, da Microsoft seit einer Weile auch “cool” und “best-buddy” sein will. Die Nutzung für Privatpersonen ist außerdem weiterhin kostenfrei.
Um die Dateien unseres “Projekts” nun komfortabel bearbeiten zu können und diese aber gleichzeitig bei GitHub gesichert zu wissen, gehen wir wie im Schaubild dargestellt vor. Schritt 1 sind wir, Schritt 2 unsere Visual Studio Code Installation, Schritt 3 die Dateien unseres Projekts und Schritt 4 die Anbindung bei GitHub.
Visual Studio Code mit GitHub verbinden
Im Terminal den Account als Standard konfigurieren, nur einmal auf eurem PC erforderlich.
Für jedes neue Projekt: Auf github.com ein neues Repository anlegen. Als nächstes in VS Code im Terminal in den Projektordner mit „cd PROJEKTNAME“ wecheseln und dann mit folgendem Befehl mit dem Repoistory verbinden
Aus einem mir nicht erklärlichen Grund, ist auf dem Mac seit geraumer Zeit das verschieben von Fenstern und Objekten mittels 3-Finger-Geste nicht mehr im Standard aktiviert. Das scheint nicht nicht nur mich gestört zu haben, da Apple einen relativ frisch aktualiserten Artikel zur Wiederherstellung dieses Verhaltens bereit stellt. Siehe hier: